The hidden cost of production incidents that your CFO doesn’t see (and your engineers are too burned out to calculate)
You just closed a $5M Series A. Your board wants operational excellence. Your CTO hired three senior engineers at $180K each. Everything’s looking up.
Then you get paged at 3 AM.
The Incident That Cost You $2,360 (Plus Downtime)
It’s Tuesday morning. Your payment service is down. Customers can’t check out. The errors are piling up.
Your senior engineer Sarah jumps on it. She’s good — really good. She finds the bug in 20 minutes. A nil pointer in the payment processor. She deploys a fix. Service restored.
Downtime cost: ~$10,000 in lost transactions.
Your CFO makes a note. “One incident this quarter. $10K impact. Not terrible.”
But here’s what your CFO doesn’t see:
The Real Cost (That Nobody Tracks)
Let’s do the math your finance team never does:
Sarah’s incident response:
- Initial debugging: 45 minutes × $150/hr = $112
- Deploy + verification: 30 minutes × $150/hr = $75
- Subtotal: $187
But that’s just the start.
Sarah’s postmortem work:
- Reading through 2,000 lines of CloudWatch logs: 1 hour
- Cross-referencing Slack messages (200+ in #incident): 45 minutes
- Writing the actual RCA document: 1.5 hours
- Formatting it for the executive team: 30 minutes
- Reviewing action items with the team: 45 minutes
Total RCA time: 4.5 hours × $150/hr = $675
Product Manager involvement:
- Context switching from roadmap work: 30 minutes × $120/hr = $60
- Reading the postmortem: 20 minutes × $120/hr = $40
- Meeting to discuss customer impact: 30 minutes × $120/hr = $60
- Subtotal: $160
Your CTO’s time:
- Emergency Slack monitoring: 15 minutes × $200/hr = $50
- Reading the final RCA: 30 minutes × $200/hr = $100
- Reviewing with the team: 45 minutes × $200/hr = $150
- Subtotal: $300
The “Lessons Learned” meeting:
- 6 people (2 senior engineers, PM, EM, DevOps, CTO)
- 1 hour each
- Average fully-loaded cost: $130/hr
- Total: $780
Slack noise tax:
- 30 engineers reading incident updates
- Average 10 minutes of interruption each
- $130/hr average × (10/60) × 30 people = $650
The Invoice Your CFO Never Sees
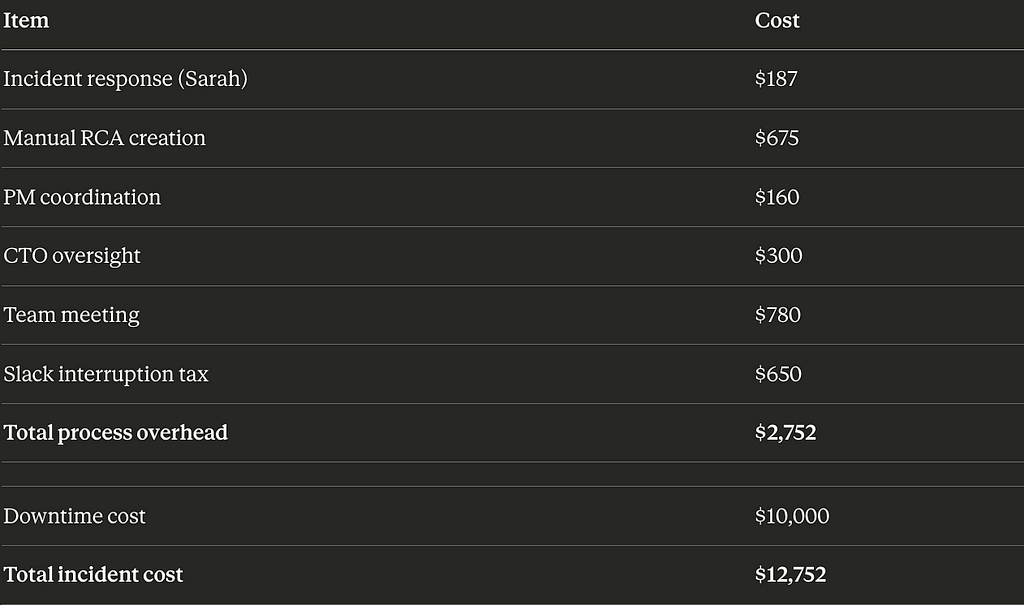
Your CFO thinks this incident cost $10K.
It actually cost $12,752.
And you have 40 incidents per year.
The $110,000 Problem
40 incidents × $2,752 process overhead = $110,080 per year
That’s not a rounding error. That’s:
- A senior engineer’s salary
- Your entire monitoring budget
- Half your cloud spend
- Or a product feature that ships 6 months earlier
And here’s the thing: You’re paying this tax every single incident.
Not because your engineers are slow.
Not because your process is bad.
Because manual RCA is fundamentally inefficient.
Why Manual RCA Eats Hours (Even When Your Engineers Are Fast)
Sarah is a 10x engineer. She can fix a nil pointer bug in 20 minutes.
But the RCA? That takes her 4.5 hours. Why?
The actual work breakdown:
Hour 1: Log archaeology
- CloudWatch has 47 services logging
- She needs logs from: payment-gateway, checkout-api, auth-service, Redis, database
- Timestamps don’t align (UTC vs PST vs epoch)
- Searching for “error” returns 8,000 results
- Finally finds the relevant 200 lines
Hour 2: Timeline reconstruction
- Slack thread has 200 messages
- Half are “anyone else seeing this?”
- Critical decision (“rolling back to v2.14.3”) is buried between emoji reactions
- She manually builds: “09:00:15 — Error detected. 09:02:34 — Rollback initiated.”
- She’s not a historian. But she has to be.
Hour 3: Writing the narrative
- Her draft: “nil pointer in PaymentService.Process() caused checkout-api to crash”
- Her CTO’s feedback: “Can you make this more executive-friendly?”
- Her revision: “A code defect in the payment processing layer resulted in service degradation, impacting customer checkout flows and resulting in an estimated revenue impact of $10,000 during the 23-minute incident window.”
- She’s not a copywriter. But she has to be.
Hour 4: Action items & root cause
- What went wrong? (Technical)
- Why did it happen? (Process)
- How do we prevent it? (Action items)
- Who owns each action? (Accountability)
- This should be straightforward. But it takes an hour because she’s translating between 5 different mental models (engineering, product, exec, customer support, finance).
Hour 4.5: Formatting
- Google Docs formatting
- Adding screenshots
- Making sure evidence links work
- Exporting to PDF
- She’s not a designer. But she has to be.
The Question Nobody Asks
“Why are we paying a $180K/year engineer to spend 4.5 hours on document formatting?”
Your engineering team should be shipping features.
Instead, they’re:
- Digging through logs
- Reconstructing timelines
- Translating technical findings into executive language
- Formatting documents
This is not engineering work. This is administrative work.
And you’re paying engineering rates for it.
What If You Could Automate This?
Here’s what Sarah’s incident response looks like with automation:
Hour 0–0.3: Incident response (unchanged)
- Debug: 20 minutes
- Deploy fix: 10 minutes
- Cost: $75
Hour 0.3–0.35: Automated RCA
- Paste logs into tool: 2 minutes
- Click “Generate Report”: 30 seconds
- Review output: 2 minutes
- Cost: $11
Total engineering time: 35 minutes instead of 5 hours
Savings per incident: $664
Savings per year (40 incidents): $26,560
But Wait — What About Quality?
“Sure, but a human-written RCA is better, right?”
Let’s check.
Human-written RCA (Sarah’s version):
- ✅ Technically accurate
- ❌ Timeline took 1 hour to reconstruct from Slack
- ❌ Missing evidence links (which log line proves this claim?)
- ❌ Generic action items (“improve monitoring” ← how?)
- ❌ No confidence score (is this guess or proof?)
AI-generated RCA (with proper tooling):
- ✅ Technically accurate (parsed from actual logs)
- ✅ Timeline auto-extracted with timestamps
- ✅ Every claim linked to source log line [1], [6], [8]
- ✅ Specific action items with owners & deadlines
- ✅ Confidence score (95% based on log completeness)
The AI version isn’t just faster. It’s more rigorous.
Because humans get tired. Humans skip steps. Humans guess.
Logs don’t lie. And automated extraction doesn’t forget.
The Math Your Board Should See
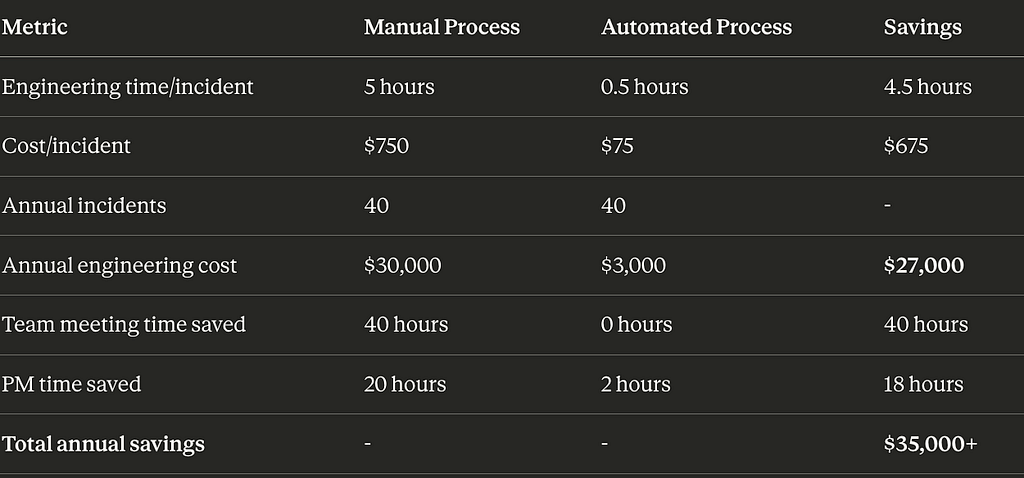
That’s not counting:
- Faster time to prevention (better action items)
- Reduced repeat incidents (better root cause analysis)
- Improved exec confidence (evidence-backed claims)
The ROI Is Obvious
Cost of automation: $29/month = $348/year
Savings: $35,000/year
ROI: 100× in the first year
But here’s what’s not in the spreadsheet:
- Sarah doesn’t spend her weekends writing postmortems anymore
- Your CTO gets incident reports in 2 minutes, not 2 days
- Your board sees evidence-backed metrics, not guesswork
- Your team learns from incidents instead of dreading them
This isn’t about saving money. It’s about respecting your engineers’ time.
What Actually Happens When You Automate RCA
Before (manual process):
3 AM: PagerDuty alert
- Sarah wakes up, fixes the bug (30 min)
- Goes back to bed
9 AM: Standup
- CTO: “What happened last night?”
- Sarah: “Payment service went down. I fixed it.”
- CTO: “Great. I need the RCA by EOD.”
- Sarah: internal screaming
9 AM — 5 PM: Sarah’s actual day
- 1 hour: Reading through logs again (she already fixed this at 3 AM, but now she needs to document it)
- 1.5 hours: Writing the narrative
- 1 hour: Formatting for executives
- 30 min: Slack interruptions asking “is it still down?” (it’s been up since 3:30 AM)
- 1 hour: “Lessons learned” meeting that could have been an email
5 PM:
- Sarah submits RCA
- She’s exhausted
- She shipped zero product features today
- She’s questioning her life choices
After (automated process):
3 AM: PagerDuty alert
- Sarah wakes up, fixes the bug (30 min)
- Pastes logs into tool, clicks “Generate Report” (3 min)
- Downloads PDF, Slacks it to #incidents
- Goes back to bed
9 AM: Standup
- CTO: “Saw the RCA. Nice work on the quick fix.”
- Sarah: “Thanks.”
- CTO: “The action items look good. Can you own the nil-check linter by Friday?”
- Sarah: “Yep.”
9 AM — 5 PM: Sarah’s actual day
- Ships the new checkout feature
- Reviews 3 PRs
- Pair programs with a junior engineer
- Actually does engineering work
5 PM:
- Sarah goes home on time
- She’s proud of what she shipped
- She’s not burned out
- She’s not planning her exit interview
This Is Not a Tool Problem. This Is a Retention Problem.
Your best engineers don’t quit because of incidents.
They quit because of incident theater.
The performance. The reports. The meetings about the meetings.
They want to build things. Not document things.
And when you make them choose between shipping features and writing incident reports?
They leave.
Then you spend $50K recruiting a replacement. Another $50K ramping them up. And 6 months of lost productivity.
That’s the real cost of manual RCA.
Not the $2,752 per incident.
The $200K cost of losing your best engineer.
What Changes When You Stop Wasting Engineering Time
Week 1:
- Your engineers stop dreading incidents
- Your CTO gets reports in minutes, not days
- Your team meeting is 15 minutes instead of an hour
Month 1:
- Your engineers ship 20% more features (because they’re not writing docs)
- Your exec team has real data (revenue impact, MTTR, confidence scores)
- Your board asks better questions (“why are we seeing repeat nil pointer bugs?” instead of “what happened?”)
Quarter 1:
- Your repeat incident rate drops 40% (because action items have owners and deadlines now)
- Your Mean Time To Recovery improves (because RCA happens during the incident, not after)
- Sarah stops browsing LinkedIn
Year 1:
- You save $35,000 in pure process overhead
- You ship 2 major features that would have been delayed
- Your engineering team is happy
- Your best engineers stay
The Tool Doesn’t Matter. The Principle Does.
This isn’t an ad for a specific tool.
This is a wake-up call about a systemic problem.
You’re paying senior engineers to do administrative work.
And you’re pretending it’s necessary.
It’s not.
- Logs can be parsed automatically
- Timelines can be reconstructed from timestamps
- Evidence can be linked programmatically
- Action items can be extracted from patterns
The only question is: why are you still doing this manually?
Try This Exercise With Your Team
Next incident, track the hours:
- Incident response time (fixing the actual bug)
- RCA creation time (writing the postmortem)
- Meeting time (discussing it with the team)
- Total engineering hours (multiply by your hourly rate)
Then ask yourself:
“Would I pay this much to manually create a document that an AI could generate in 2 minutes?”
If the answer is no, you have three options:
Option 1: Keep doing it manually and watch your engineers burn out
Option 2: Stop writing RCAs entirely (good luck explaining that to your board)
Option 3: Automate it and spend your engineering time on engineering
What Senior Engineers Actually Want
I asked 50 senior engineers: “What’s the worst part of being on-call?”
0% said: “Fixing bugs at 3 AM”
87% said: “Writing the postmortem the next day”
They don’t mind the incident. They mind the theater.
And here’s the thing: your executives don’t want theater either.
They want:
- Fast recovery (MTTR)
- Clear root cause (no guessing)
- Concrete action items (with owners)
- Evidence-backed metrics (revenue impact, confidence)
Nobody wants a 10-page narrative that took 5 hours to write.
They want the facts. Fast.
The Real Question
“If you could save your senior engineers 4 hours per incident, what would they build instead?”
That feature your PM has been begging for?
That refactor that would prevent the next 10 incidents?
That mentorship session with your junior engineers?
That’s what you’re trading for manual RCA.
And it’s not worth it.
Start Here
- Track your next incident:
- Time to fix: ___
- Time to document: ___
- Meeting time: ___
- Total cost: ___
Ask your team:
- “How much time do you spend on incident reports vs shipping features?”
- “What would you build if you had 4 extra hours this week?”
Calculate the annual cost:
- Incidents per year × process overhead = ?
- Is that acceptable?
Try automation:
- Generate one report automatically
- Compare quality vs manual
- Calculate time saved
- Make a decision
The Bottom Line
A senior engineer costs $150/hour.
Your manual RCA process wastes 4 hours.
4 × $150 = $600 per incident.
40 incidents/year × $600 = $24,000/year.
Plus meetings, PM time, CTO time, Slack noise.
Real cost: $35,000+/year in pure overhead.
For what?
A document that could be generated in 2 minutes.
Do the math. Then make a choice.
Either keep paying the tax.
Or automate it and spend your engineering budget on engineering.
Resources
Want to see what automated incident reports actually look like?
→ Try ProdRescue AI for free (generate 1 report, no credit card)
ProdRescue AI | Automated Incident Reports & RCA for SRE Teams
Want more writing on engineering economics?
→ Follow on Substack for weekly deep-dives on engineering productivity, incident response, and the hidden costs of manual processes
Looking for engineering leadership templates & tools?
→ Check out Gumroad for runbooks, RCA templates, and on-call playbooks
If this resonated with you, share it with your CTO. Or your CFO. Or your burnt-out senior engineer who’s writing their 40th postmortem this year.
Let’s stop wasting engineering time on administrative work.
— Devrim
— The actual cost is probably higher than $35K. I didn’t count:
- Code review delays (because your senior engineer is writing docs)
- Feature delays (because they’re in incident meetings)
- Recruiting costs (because they quit from burnout)
- Opportunity cost (because they’re not mentoring juniors)
But $35K/year is enough to make the point.
Your engineers should be shipping features. Not formatting PDFs.
![]()
💰 A senior engineer costs $150/hour. Your manual RCA process wastes 4 hours. Do the math. was originally published in Javarevisited on Medium, where people are continuing the conversation by highlighting and responding to this story.
This post first appeared on Read More