AI coding assistants are powerful but only as good as their understanding of your codebase. When we pointed AI agents at one of Meta’s large-scale data processing pipelines – spanning four repositories, three languages, and over 4,100 files – we quickly found that they weren’t making useful edits quickly enough.
We fixed this by building a pre-compute engine: a swarm of 50+ specialized AI agents that systematically read every file and produced 59 concise context files encoding tribal knowledge that previously lived only in engineers’ heads. The result: AI agents now have structured navigation guides for 100% of our code modules (up from 5%, covering all 4,100+ files across three repositories). We also documented 50+ “non-obvious patterns,” or underlying design choices and relationships not immediately apparent from the code, and preliminary tests show 40% fewer AI agent tool calls per task. The system works with most leading models because the knowledge layer is model-agnostic.
The system also maintains itself. Every few weeks, automated jobs periodically validate file paths, detect coverage gaps, re-run quality critics, and auto-fix stale references. The AI isn’t a consumer of this infrastructure, it’s the engine that runs it.
The Problem: AI Tools Without a Map
Our pipeline is config-as-code: Python configurations, C++ services, and Hack automation scripts working together across multiple repositories. A single data field onboarding touches configuration registries, routing logic, DAG composition, validation rules, C++ code generation, and automation scripts – six subsystems that must stay in sync.
We had already built AI-powered systems for operational tasks, scanning dashboards, pattern-matching against historical incidents, and suggesting mitigations. But when we tried to extend it to development tasks, it fell apart. The AI had no map. It didn’t know that two configuration modes use different field names for the same operation (swap them and you get silent wrong output), or that dozens of “deprecated” enum values must never be removed because serialization compatibility depends on them.
Without this context, agents would guess, explore, guess again and often produce code that compiled but was subtly wrong.
The Approach: Teach the Agents Before They Explore
We used a large-context-window model and task orchestration to structure the work in phases:
- Two explorer agents mapped the codebase,
- 11 module analysts read every file and answered five key questions,
- Two writers generated context files, and
- 10+ critic passes ran three rounds of independent quality review,
- Four fixers applied corrections,
- Eight upgraders refined the routing layer,
- Three prompt testers validated 55+ queries across five personas,
- Four gap-fillers covered remaining directories, and
- Three final critics ran integration tests – 50+ specialized tasks orchestrated in a single session.
The five questions each analyst answered per module:
- What does this module configure?
- What are the common modification patterns?
- What are the non-obvious patterns that cause build failures?
- What are the cross-module dependencies?
- What tribal knowledge is buried in code comments?
Question five was where the deepest learnings emerged. We found 50+ non-obvious patterns like hidden intermediate naming conventions where one pipeline stage outputs a temporary field name that a downstream stage renames (reference the wrong one and code generation silently fails), or append-only identifier rules where removing a “deprecated” value breaks backward compatibility. None of this had been written down before.
What We Built: A Compass, Not An Encyclopedia
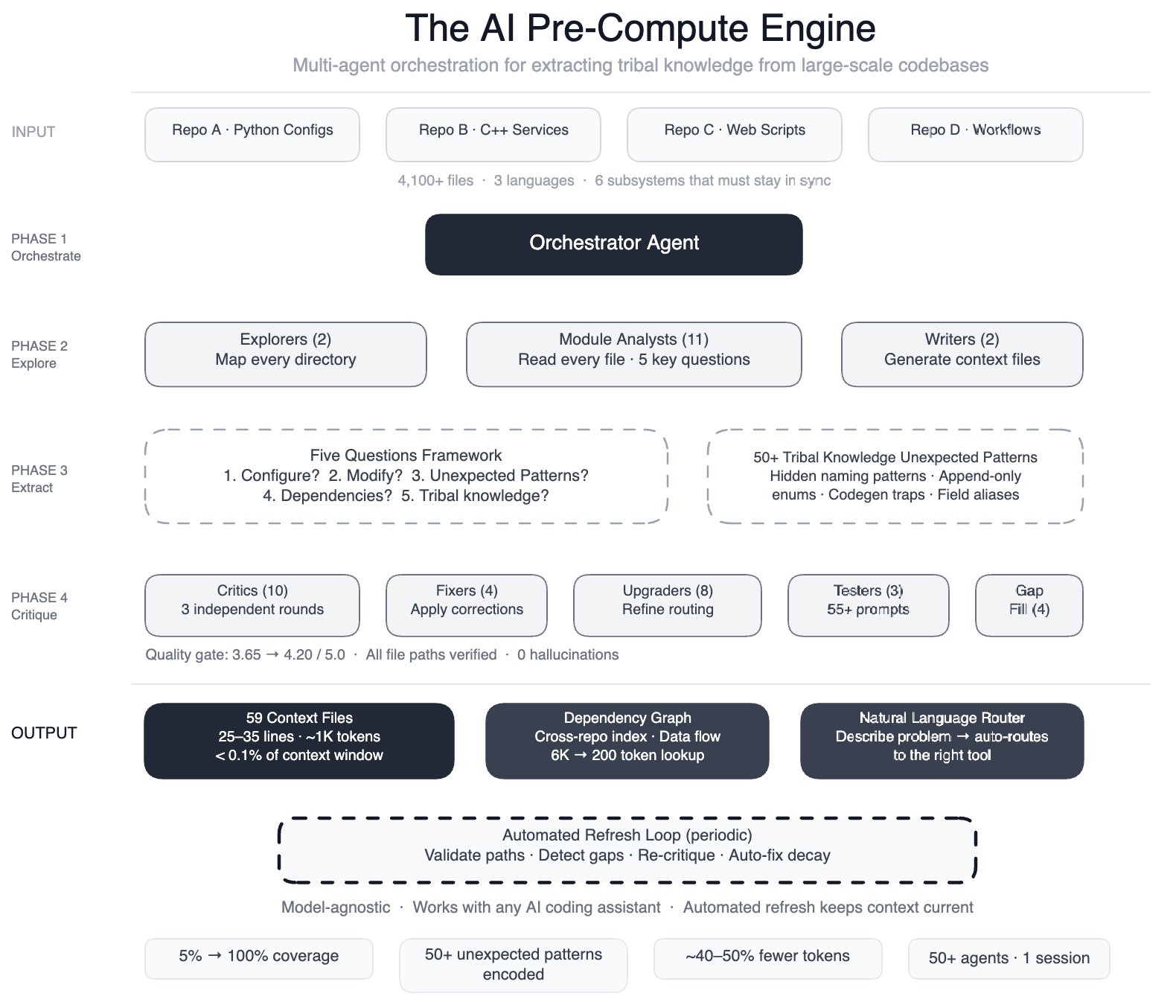
Each context file follows what we call “compass, not encyclopedia” principle – 25–35 lines (~1,000 tokens) with four sections:
- Quick Commands (copy-paste operations).
- Key Files (the 3–5 files you actually need).
- Non-Obvious patterns.
- See Also (cross-references).
No fluff, every line earns its place. All 59 files together consume less than 0.1% of a modern model’s context window.
On top of this, we built an orchestration layer that auto-routes engineers to the right tool based on natural language. Type, “Is the pipeline healthy?” and it scans dashboards and matches against 85+ historical incident patterns. Type, “Add a new data field” and it generates the configuration with multi-phase validation. Engineers describe their problem; the system figures out the rest.
The system self-refreshes every few weeks, validating file paths, identifying coverage gaps, re-running critic agents, and auto-fixing issues. Context that decays is worse than no context at all.
Beyond individual contextual files, we generated a cross-repo dependency index and data flow maps showing how changes propagate across repositories. This turns “What depends on X?” from a multi-file exploration (~6000 tokens) into a single graph lookup (~200 tokens) – in config-as-code where one field change ripples across six-subsystems.
Results
| Metric | Before | After |
| AI context coverage | ~5% (5 files) | 100% (59 files) |
| Codebase files with AI navigation | ~50 | 4,100+ |
| Tribal knowledge documented | 0 | 50+ non-obvious patterns |
| Tested prompts (core pass rate) | 0 | 55+ (100%) |
In preliminary tests on six tasks against our pipeline, agents with pre-computed context used roughly 40% fewer tool calls and tokens per task. Complex workflow guidance that previously required ~two days of research and consulting with engineers now completes in ~30 minutes.
Quality was non-negotiable: three rounds of independent critic agents improved scores from 3.65 to 4.20 out of 5.0, and all referenced file paths were verified with zero hallucinations.
Challenging the Conventional Wisdom on AI Context Files
Recent academic research found that AI-generated context files actually decreased agent success rates on well-known open-source Python repositories. This finding deserves serious consideration but it has a limitation: It was evaluated on codebases like Django and matplotlib that models already “know” from pretraining. In that scenario, context files are redundant noise.
Our codebase is the opposite: proprietary config-as-code with tribal knowledge that exists nowhere in any model’s training data. Three design decisions help us avoid the pitfalls the research identified: files are concise (~1,000 tokens, not encyclopedic summaries), opt-in (loaded only when relevant, not always-on), and quality-gated (multi-round critic review plus automated self-upgrade).
The strongest argument: Without context, agents burn 15–25 tool calls exploring, miss naming patterns, and produce subtly incorrect code. The cost of not providing context is measurably higher.
How to Apply This to Your Codebase
This approach isn’t specific to our pipeline. Any team with a large, proprietary codebase can benefit:
- Identify your tribal knowledge gaps. Where do AI agents fail most? The answer is usually domain-specific conventions and cross-module dependencies that aren’t documented anywhere.
- Use the “five questions” framework. Have agents (or engineers) answer: what does it do, how do you modify it, what breaks, what depends on it, and what’s undocumented?
- Follow “compass, not encyclopedia.“ Keep context files to 25–35 lines. Actionable navigation beats exhaustive documentation.
- Build quality gates. Use independent critic agents to score and improve generated context. Don’t trust unreviewed AI output.
- Automate freshness. Context that goes stale causes more harm than no context. Build periodic validation and self-repair.
What’s Next
We are expanding context coverage to additional pipelines across Meta’s data infrastructure and exploring tighter integration between context files and code generation workflows. We’re also investigating whether the automated refresh mechanism can detect not just stale context but emerging patterns and new tribal knowledge forming in recent code reviews and commits.
This approach turned undocumented tribal knowledge into structured, AI-readable context and one that compounds with every task that follows.
The post How Meta Used AI to Map Tribal Knowledge in Large-Scale Data Pipelines appeared first on Engineering at Meta.
This post first appeared on Read More