In a recent design review, the customer’s application was in production, but performance had taken a nosedive as data volumes grew. It turned out that the issue was down to how they were indexing the embedded objects in their documents. This article explains why their indexes were causing problems, and how they could be fixed.
Note that I’ve changed details for this use case to obfuscate the customer and application. All customer information shared in a design review is kept confidential.
We looked at the schema, and things looked good. They’d correctly split their claim information across two documents:
One contained a modest amount of queryable data (20 KB per claim). These documents included the _id of the second document in case the application needed to fetch it (which was relatively rare).
The second contained the bulky raw data that’s immutable, unindexed, and rarely read.
They had 110K queryable documents in the first collection—claims.
With 2.2 GB of documents (before compression, which only reduces on-disk size) and 4 GB of cache, there shouldn’t have been any performance issues. We looked at some of the queries, and there was a pretty wide set of keys being filtered on and in different combinations, but none of them returned massive numbers of documents.
Some queries were taking tens of seconds.
It made no sense. Even a full collection scan should take well under a second for this configuration. And they’d even added indexes for their common queries. So then, we looked at the indexes…

15 indexes on one collection is on the high side and could slow down your writes, but it’s the read performance that we were troubleshooting.
But, those 15 indexes are consuming 85 GB of space. With the 4 GB of cache available on their M30 Atlas nodes, that’s a huge problem!
There wasn’t enough RAM in the system for the indexes to fit in cache. The result was that when MongoDB navigated an index, it would repeatedly hit branches that weren’t yet in memory and then have to fetch them from disk. That’s slow.
Taking a look at one of the indexes…

It’s a compound index on six fields, but the first five of those fields are objects, and the sixth is an array of objects—this explains why the indexes were so large.
Avoiding indexes on objects
Even ignoring the size of the index, adding objects to an index can be problematic. Querying on embedded objects doesn’t behave in the way that many people expect. If an index on an embedded object is to be used, then the query needs to include every field in the embedded object. E.g., if I execute this query, then it matches exactly one of the documents in the database:
db.getCollection('claim').findOne(
 {
 "policy_holder": {
 "first_name": "Janelle",
 "last_name": "Nienow",
 "dob": new Date("2024-12-16T23:56:49.643Z"),
 "location": {
 "street": "67628 Warren Road",
 "city": "Padbergstead",
 "state": "Minnesota",
 "zip_code": "44832-7187"
 },
 "contact": {
 "email": "[email protected]"
 }
 }
 }
);
It delivers this result:
{
 "_id": {
 "$oid": "67d801b7ad415ad6165ccd5f"
 },
 "region": 12,
 "policy_holder": {
 "first_name": "Janelle",
 "last_name": "Nienow",
 "dob": {
 "$date": "2024-12-16T23:56:49.643Z"
 },
 "location": {
 "street": "67628 Warren Road",
 "city": "Padbergstead",
 "state": "Minnesota",
 "zip_code": "44832-7187"
 },
 "contact": {
 "email": "[email protected]"
 }
 },
 "policy_details": {
 "policy_number": "POL554359100",
 "type": "Home Insurance",
 "coverage": {
 "liability": 849000000,
 "collision": 512000,
 "comprehensive": 699000
 }
 },
 ...
}
The explain plan confirmed that MongoDB was able to use one of the defined indexes:
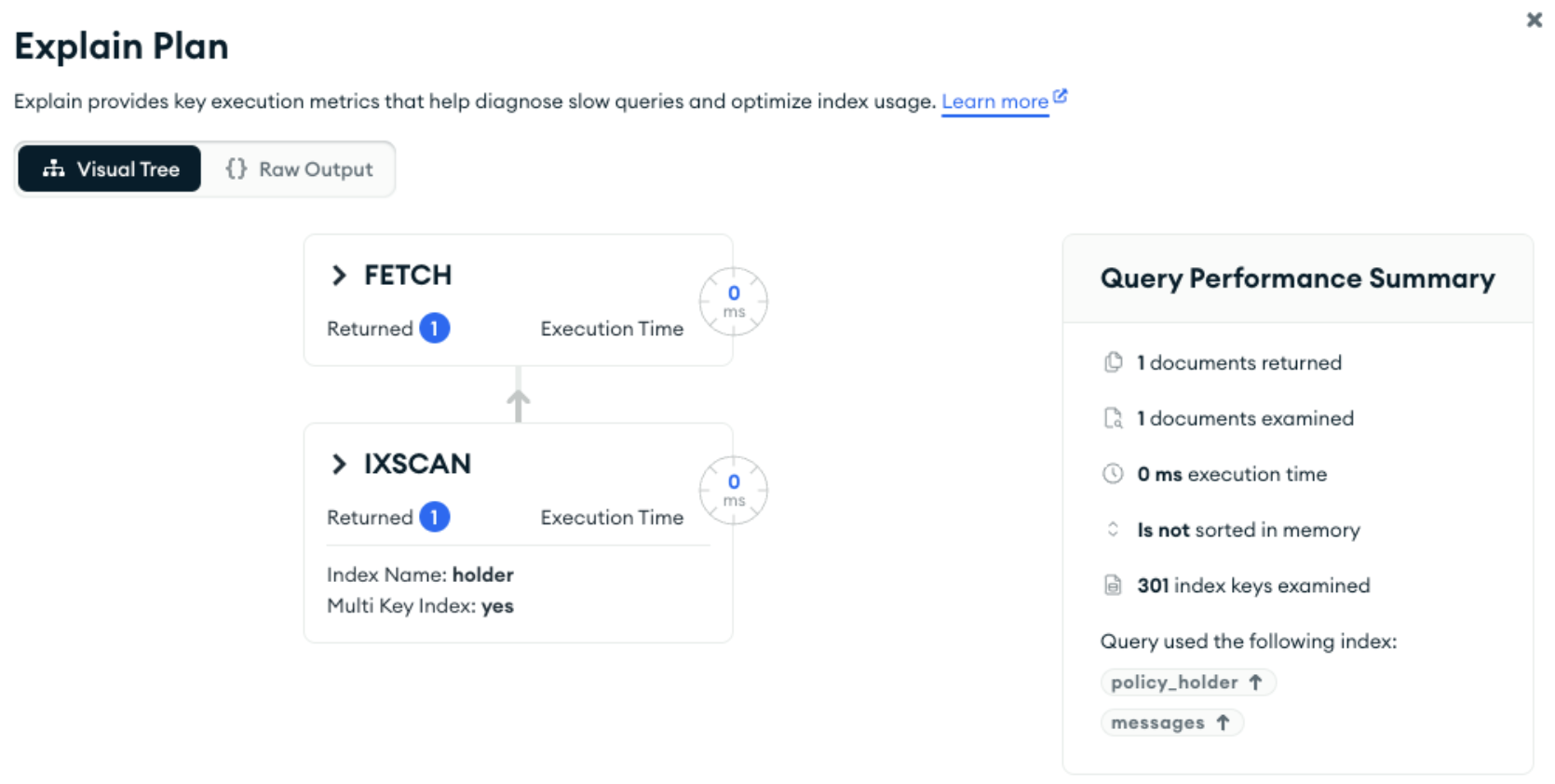
If just one field from the embedded object isn’t included in the query, then no documents will match:
db.getCollection('claim').findOne(
 {
 "policy_holder": {
 "first_name": "Janelle",
 "last_name": "Nienow",
 "dob": new Date("2024-12-16T23:56:49.643Z"),
 "location": {
 "street": "67628 Warren Road",
 "city": "Padbergstead",
 "state": "Minnesota",
 // "zip_code": "44832-7187"
 },
 "contact": {
 "email": "[email protected]"
 }
 }
 }
);
This resulted in no matches—though the index is at least still used.
If we instead pick out individual fields from the object to query on, then we get the results we expect:
db.getCollection('claim').findOne(
 {
 "policy_holder.first_name": "Janelle",
 "policy_holder.last_name": "Nienow"
 }
);
{
 "_id": {
 "$oid": "67d801b7ad415ad6165ccd5f"
 },
 "region": 12,
 "policy_holder": {
 "first_name": "Janelle",
 "last_name": "Nienow",
 "dob": {
 "$date": "2024-12-16T23:56:49.643Z"
 },
 "location": {
 "street": "67628 Warren Road",
 "city": "Padbergstead",
 "state": "Minnesota",
 "zip_code": "44832-7187"
 },
 "contact": {
 "email": "[email protected]"
 }
 },
 "policy_details": {
 "policy_number": "POL554359100",
 "type": "Home Insurance",
 "coverage": {
 "liability": 849000000,
 "collision": 512000,
 "comprehensive": 699000
 }
 },
 ...
}
Unfortunately, none of the indexes that included policy_holder could be used as they were indexing the value of the complete embedded object, not the individual fields within it, and so a full collection scan was performed:
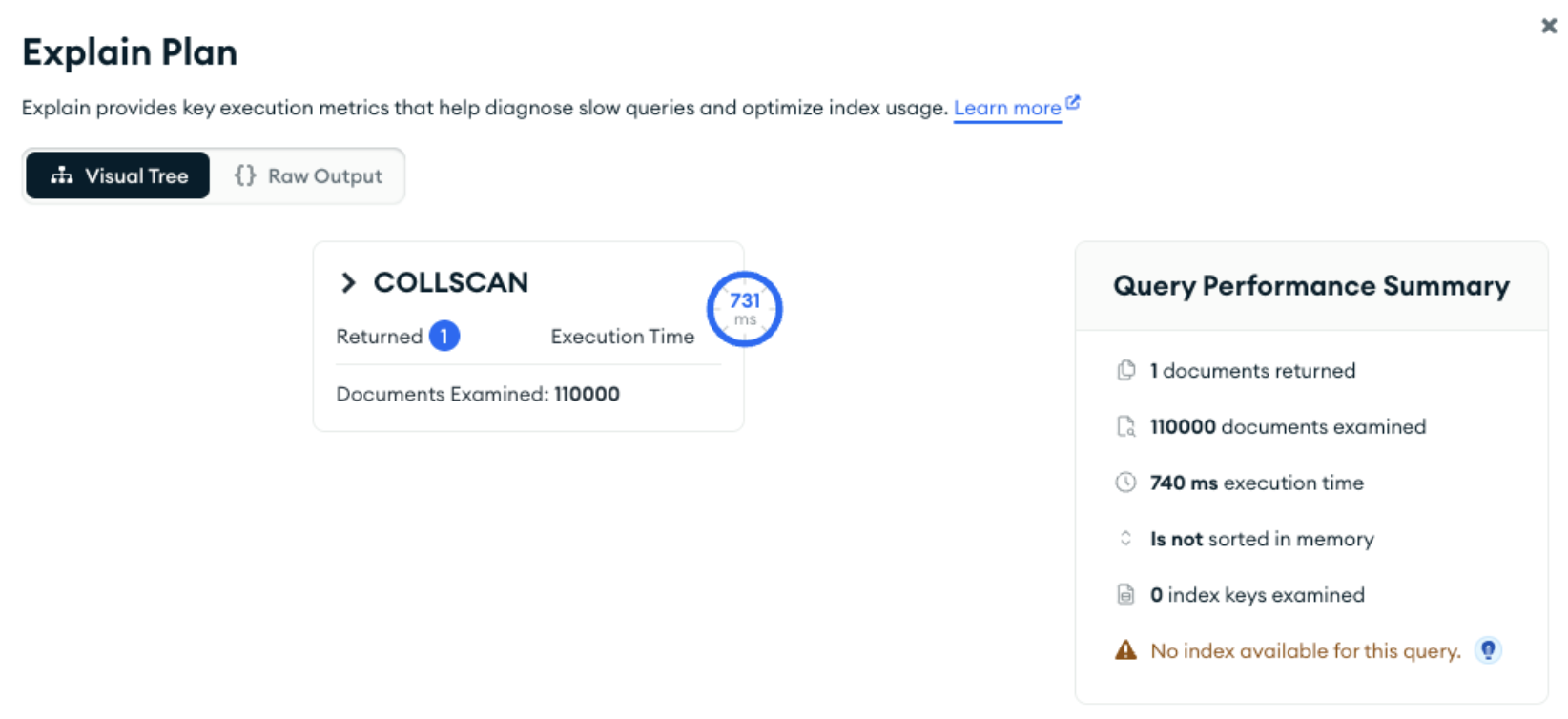
Using compound indexes instead
If we instead add a compound index that leads with the fields from the object we need to filter on, then that index will be used:
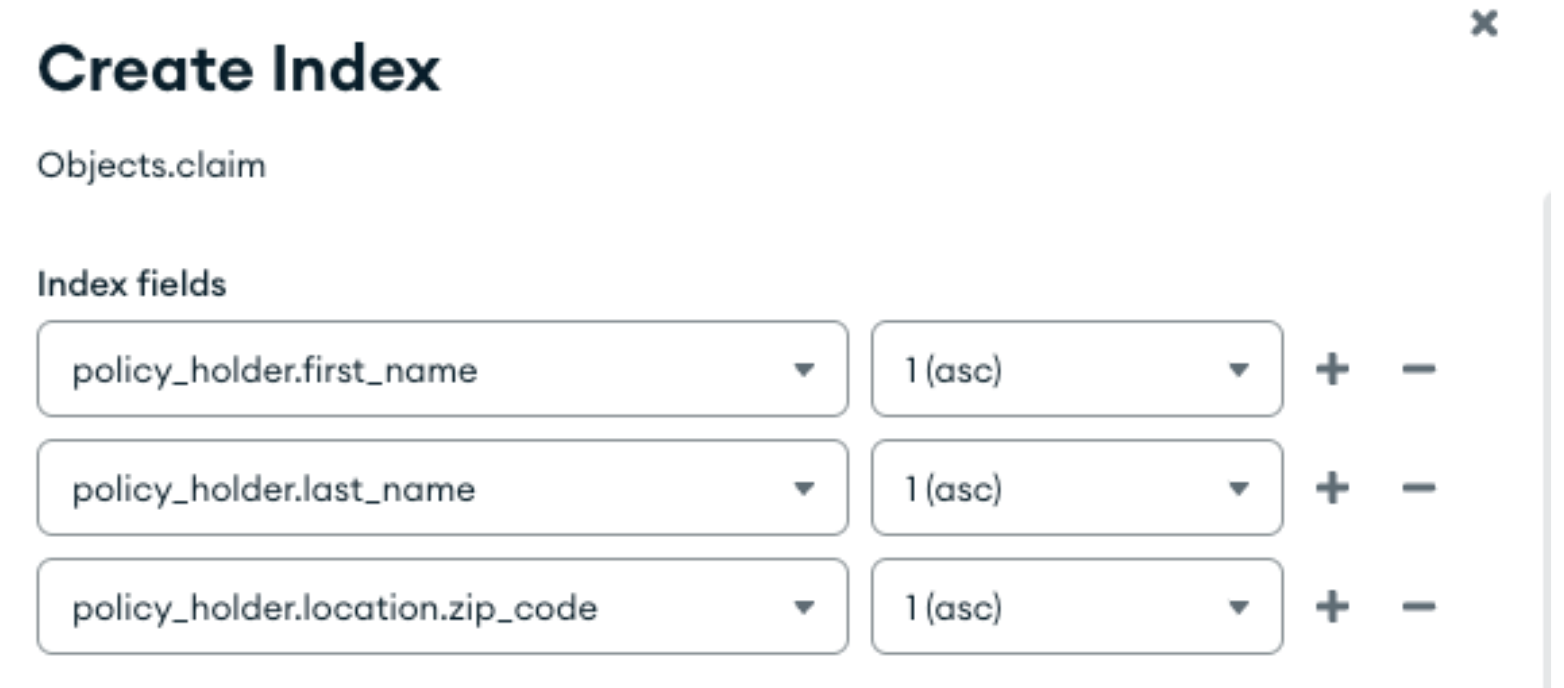
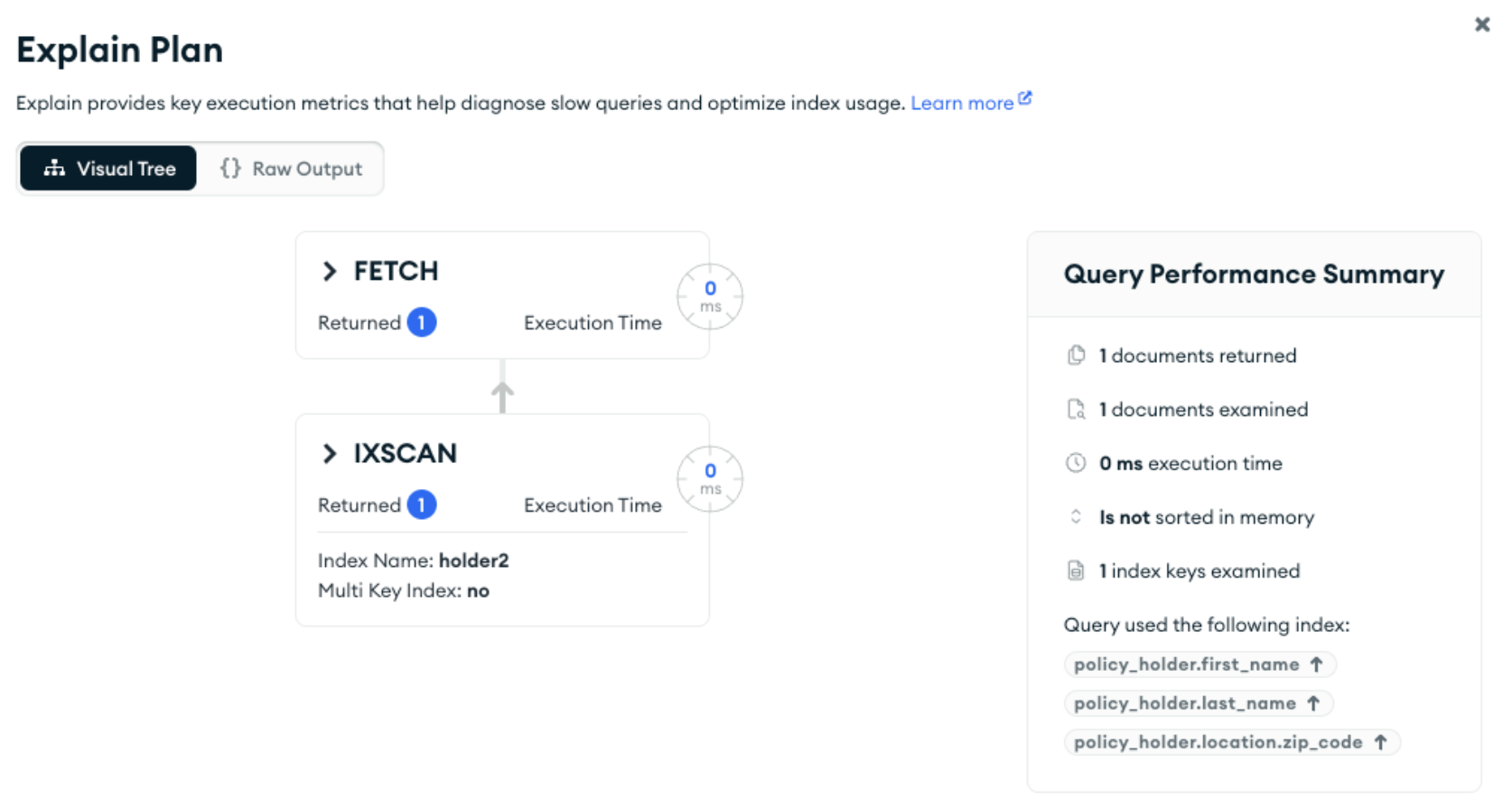
As a quick refresher on using compound indexes, that index will be used if we query on just first_name:
db.getCollection('claim').findOne(
 {
 "policy_holder.first_name": "Janelle",
 // "policy_holder.last_name": "Nienow"
 }
);
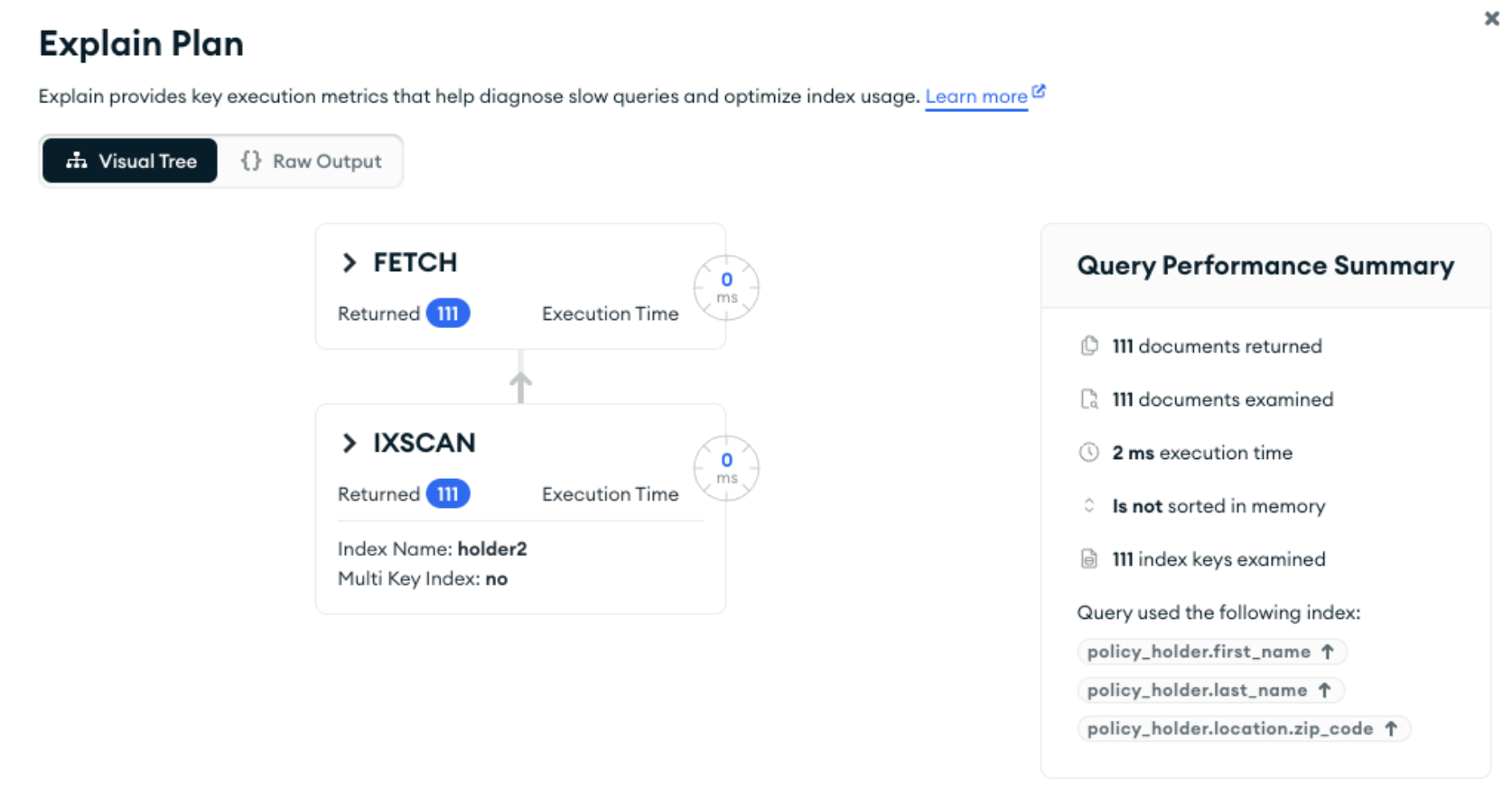
If we don’t include the first key in the compound index, then it won’t be used:
db.getCollection('claim').findOne(
 {
 // "policy_holder.first_name": "Janelle",
 "policy_holder.last_name": "Nienow"
 }
);
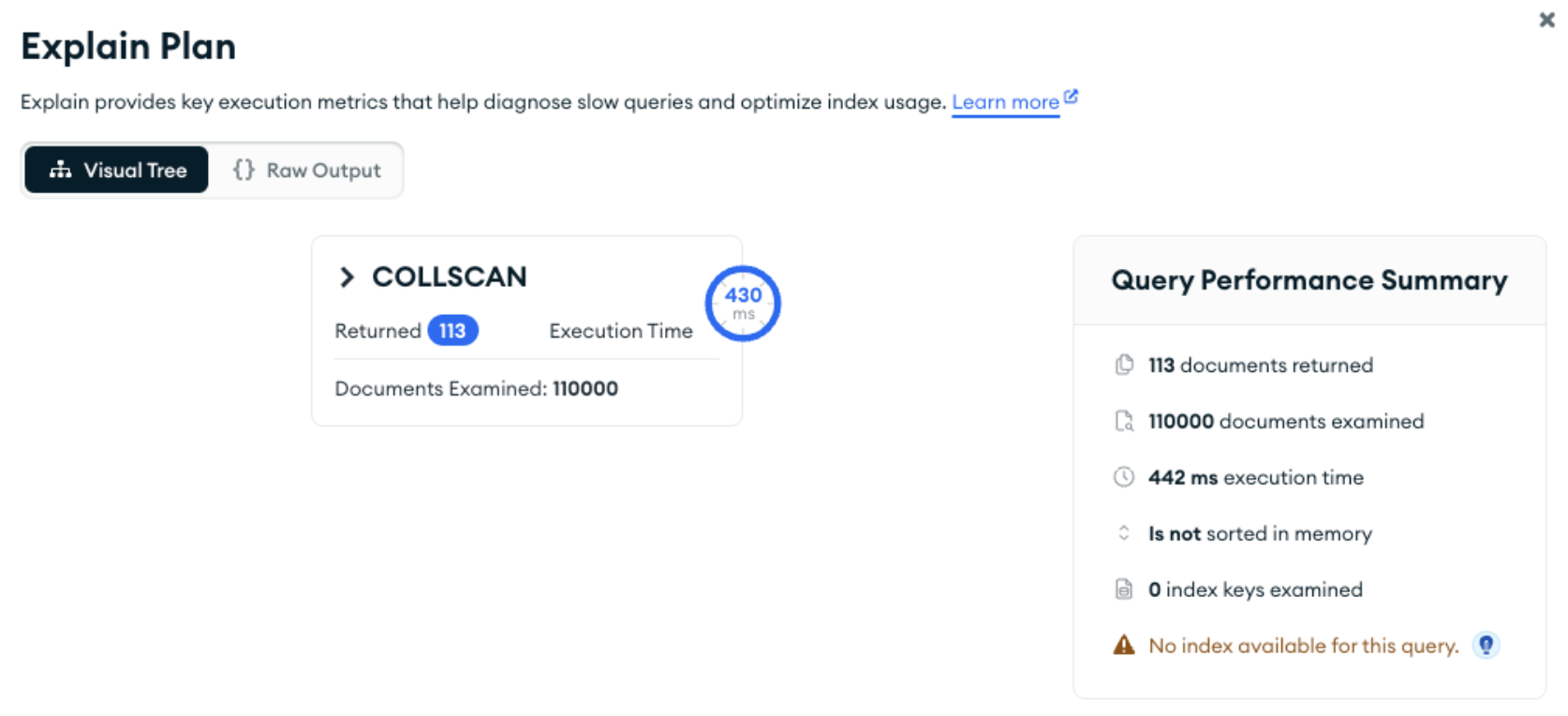
However, you can use the index if you artificially include the leading keys in the query (though it will be more efficient if last_name had been the first key in the index):
db.getCollection('claim').findOne(
 {
 "policy_holder.first_name": {$exists: true},
 "policy_holder.last_name": "Nienow"
 }
);
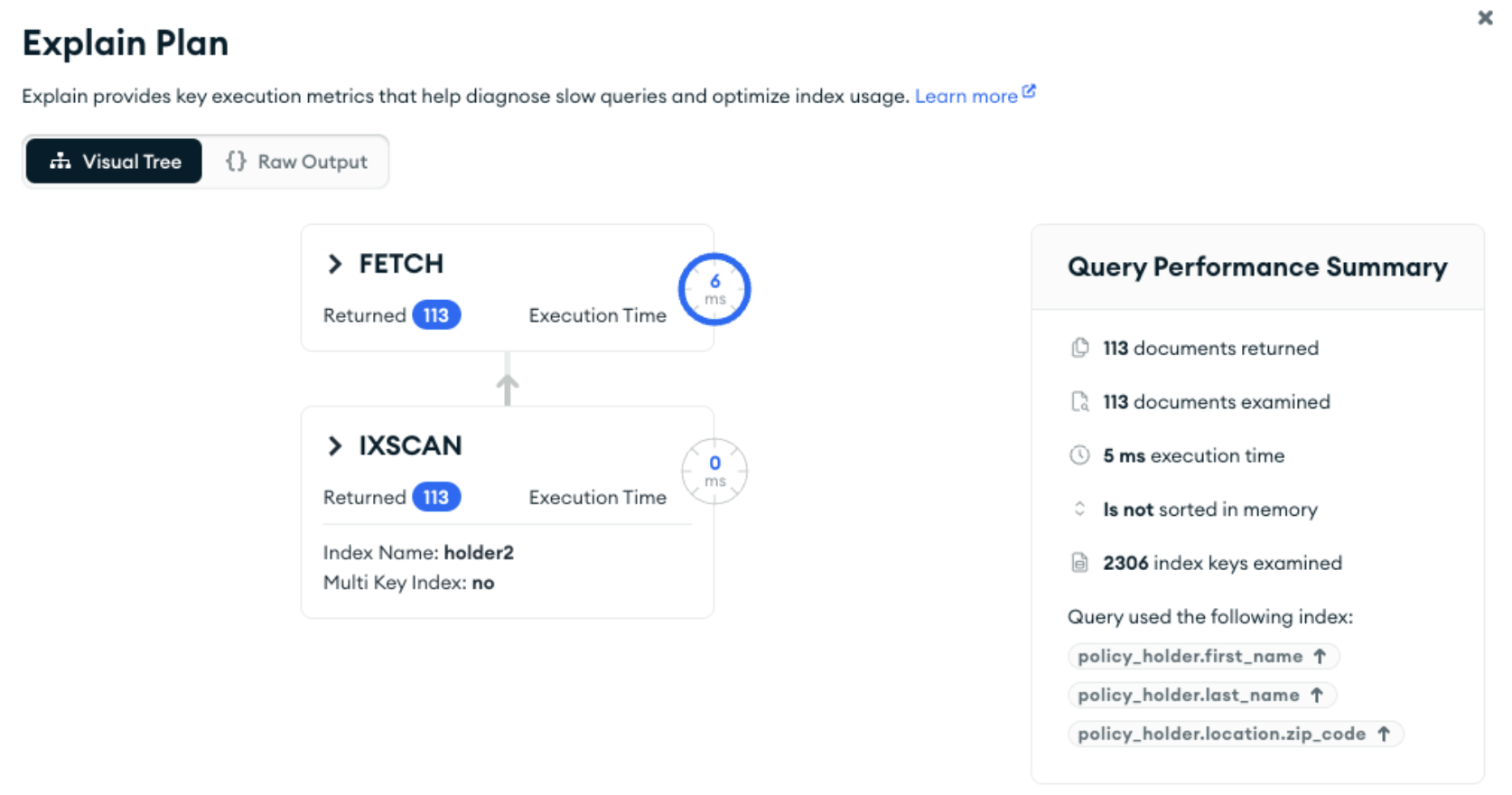
Incompletely indexed queries
While having indexes for your queries is critical, there is a cost to having too many, or in having indexes that include too many fields—writes get slower and pressure increases on cache occupancy.
Sometimes, it’s enough to have an index that does part of the work, and then rely on a scan of the documents found by the index to check the remaining keys.
For example, the policy holder’s home state isn’t included in our compound index, but we can still query on it:
db.getCollection('claim').findOne(
 {
 "policy_holder.first_name": "Janelle",
 "policy_holder.location.state": "Kentucky"
 }
);
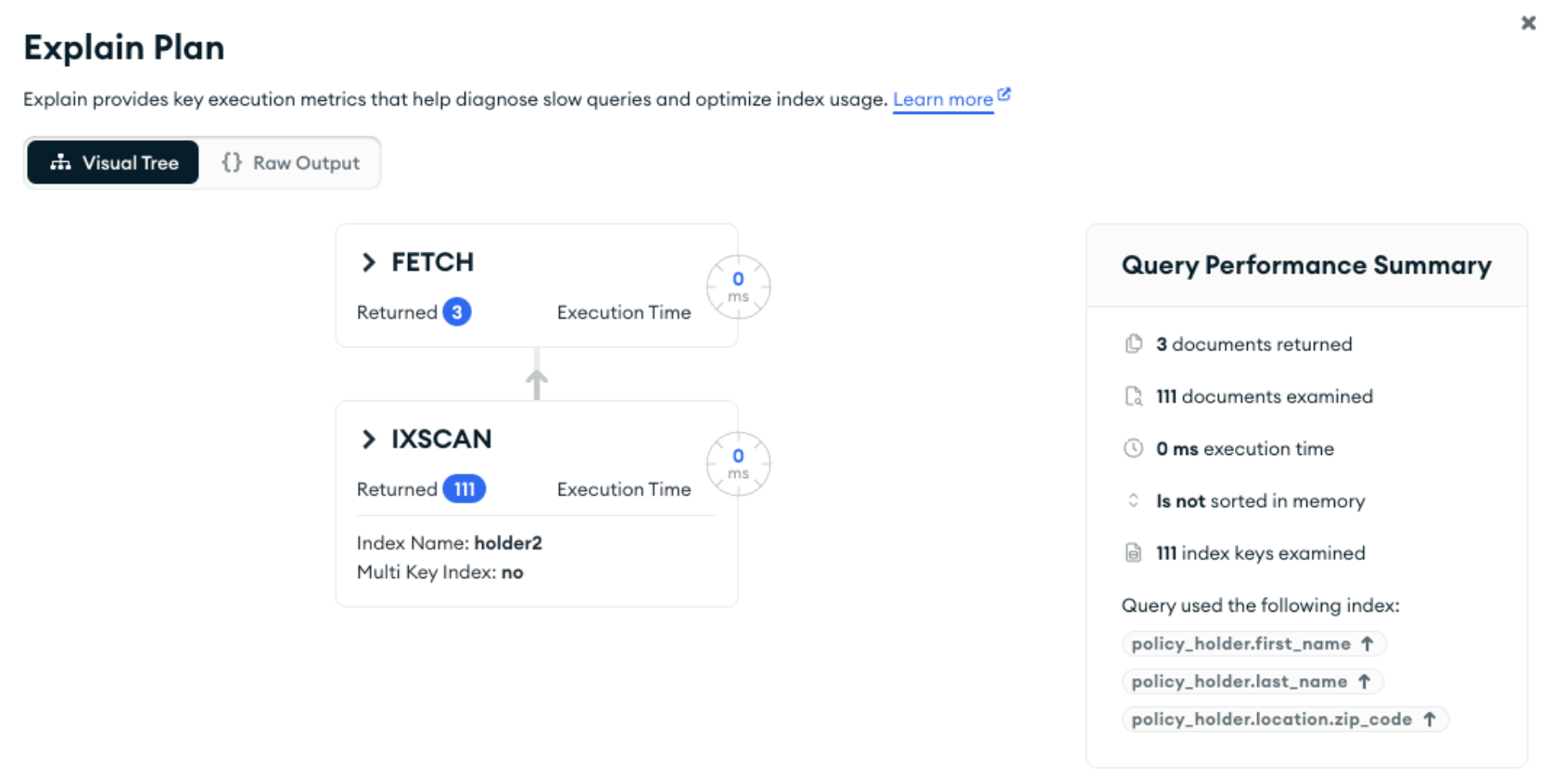
The explain plan shows that the index narrowed down the search from 110,000 documents to 111, which were then scanned to find the three matching documents. If it’s rare for the state to be included in the query, then this can be a good solution.
Partial indexes
The main challenge in this design review was the size of the indexes, and so it’s worth looking into another approach to limit the size of an index.
Imagine that we need to be able to check on the names and email addresses of witnesses to accidents. We can add an index on the relevant fields:

This index consumes 9.8 MB of cache space and must be updated when any document is added, or when any of these three fields are updated.
Even if a document has null values for the indexed fields, or if the fields aren’t even present in the document, the document will still be included in the index.
If we look deeper into the requirements, we might establish that we only need to query this data for fraudulent claims. That means that we’re wasting space in our index for entries for all of the other claims.
We can exploit this requirement by creating a partial index, setting the partial filter expression to { "claim.status": "Fraud" }. Only documents that match that pattern will be included in the index.
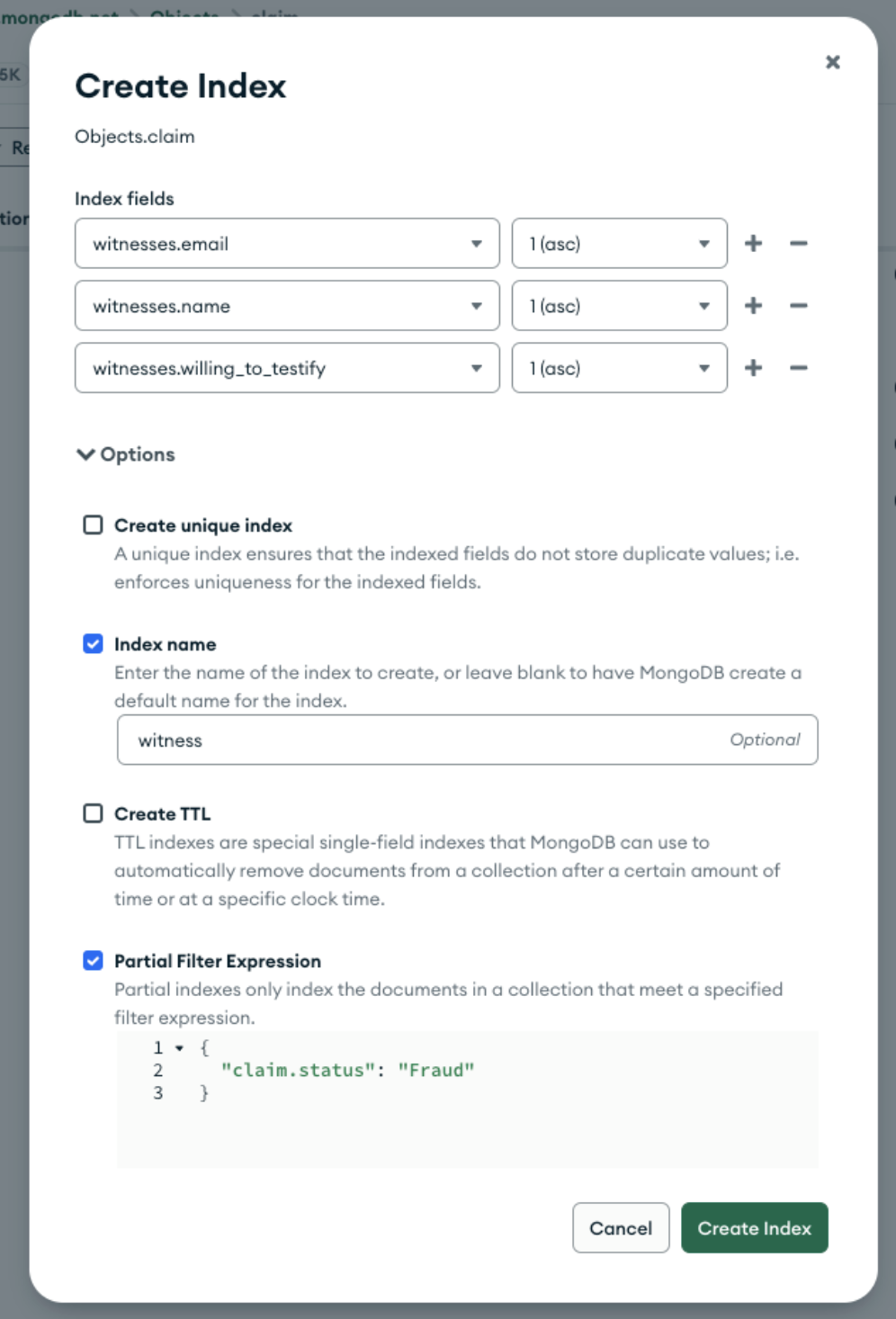
That reduces the size of the index to 57 KB (a saving of more than 99%):

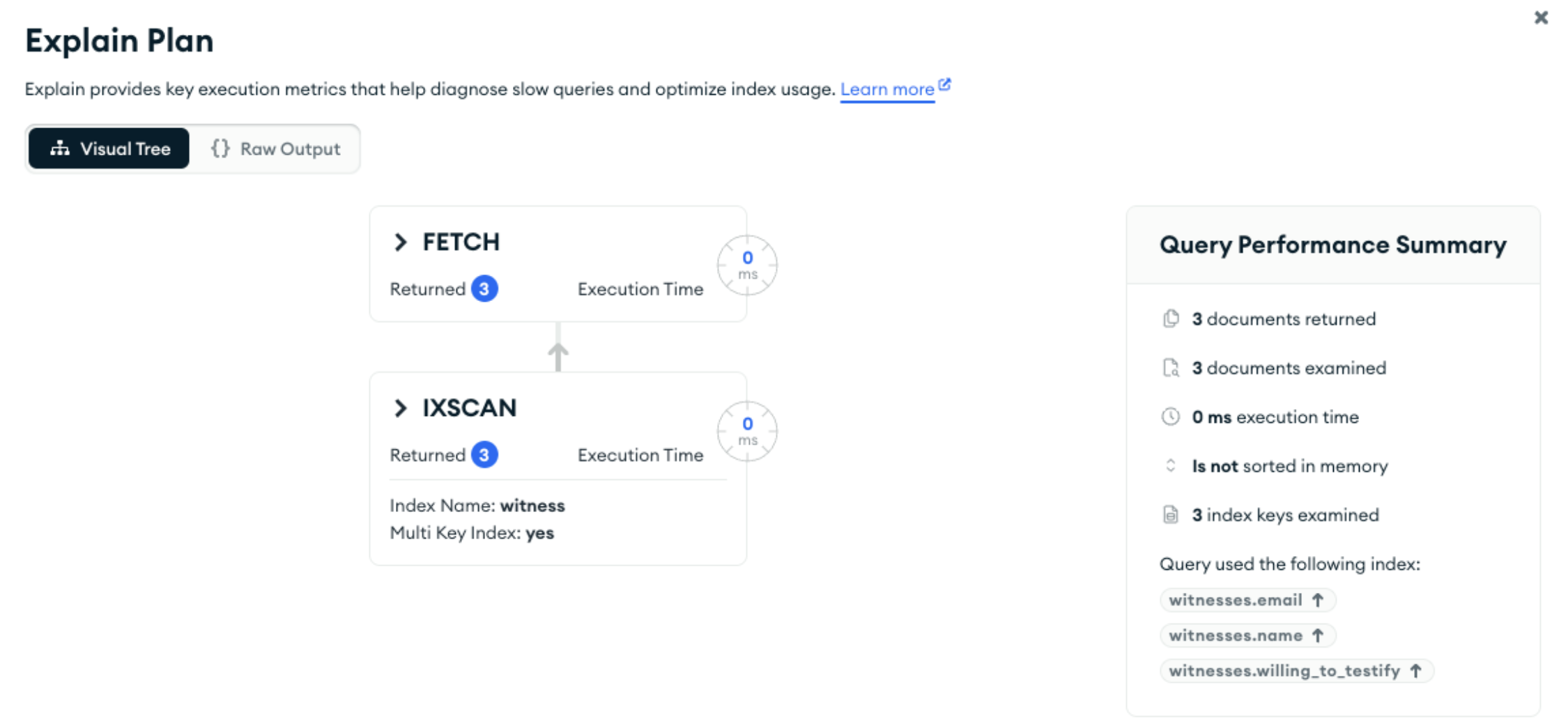
Note that queries must include { “claim.status”: “Fraud” } for this index to be used:
db.getCollection('claim').findOne(
 {
 "witnesses.email": "[email protected]",
 "claim.status": "Fraud" 
 }
);
Conclusion
Indexes are critical to database performance, whether you’re using an RDBMS or MongoDB.
MongoDB allows polymorphic documents, arrays, and embedded objects that aren’t available in a traditional RDBMS. This leads to extra indexing opportunities, but also potential pitfalls.
You should have indexes to optimize all of your frequent queries, but use the wrong type or too many of them and things could backfire. We saw that in this case with indexes taking up too much space and not being as general purpose as the developer believed.
To compound problems, the database may perform well in development and for the early days in production. Things go wrong over time as the collections grow and extra indexes are added. As soon as the working data set (indexes and documents) doesn’t fit in the cache, performance quickly declines.
Well-informed use of compound and partial indexes will ensure that MongoDB delivers the performance your application needs, even as your database grows.
Learn more about MongoDB design reviews
Design reviews are a chance for a design expert from MongoDB to advise you on how best to use MongoDB for your application. The reviews are focused on making you successful using MongoDB.
It’s never too early to request a review. By engaging us early (perhaps before you’ve even decided to use MongoDB), we can advise you when you have the best opportunity to act on it.
This article explained how using a MongoDB schema and set of indexes that match how your application works with data can meet your performance requirements. If you want help to come up with that schema, then a design review is how to get that help.
Would your application benefit from a review? Schedule your design review today.
Want to read more from Andrew? Head to his website.
This article first appeared on Read More