Retrieval-augmented generation (RAG) is becoming increasingly vital for developing sophisticated AI applications that not only generate fluent text but also ensure precision and contextual relevance by grounding responses in real, factual data. This approach significantly mitigates hallucinations and enhances the reliability of AI outputs.
This guide provides a detailed exploration of an open-source solution designed to facilitate the deployment of a production-ready RAG application by using the powerful combination of MongoDB Atlas and Cohere Command R+. This solution is built upon and extends the foundational principles demonstrated in the official Cohere plus MongoDB RAG documentation available at Build Chatbots with MongoDB and Cohere.
To provide you with in-depth knowledge and practical skills in several key areas, this comprehensive walkthrough will:
Show you how to build a complete RAG pipeline using MongoDB Atlas and Cohere APIs
Focus on data flow, retrieval, and generation
Enable you to enhance answer quality through reranking to improve relevance and accuracy
Enable detailed, flexible deployment with Docker Compose for local or cloud environments
Explain MongoDB’s dual role as a vector store and chat memory for a seamless RAG application
Reasons to choose MongoDB and Cohere for RAG
The convergence of powerful technologies—MongoDB Atlas and Cohere Command R+—unlocks significant potential for creating sophisticated, scalable, and high-performance systems for grounded generative AI (gen AI). This synergistic approach provides a comprehensive toolkit to handle the unique demands of modern AI applications.
MongoDB Atlas and Cohere Command R+ facilitate the development of scalable, high-performing, and grounded AI applications.
MongoDB Atlas provides a scalable, flexible, reliable, and fast database for managing large datasets used to ground generative models.
Cohere Command R+ offers a sophisticated large language model (LLM) for natural language understanding and generation, incorporating retrieved data for factual accuracy and rapid inference.
The combined use of MongoDB Atlas and Cohere Command R+ results in applications with fast and accurate responses, scalable architectures, and outputs informed by real-world data.
This powerful combination represents a compelling approach to building the next generation of gen AI applications, facilitating innovation and unlocking novel opportunities across various sectors.
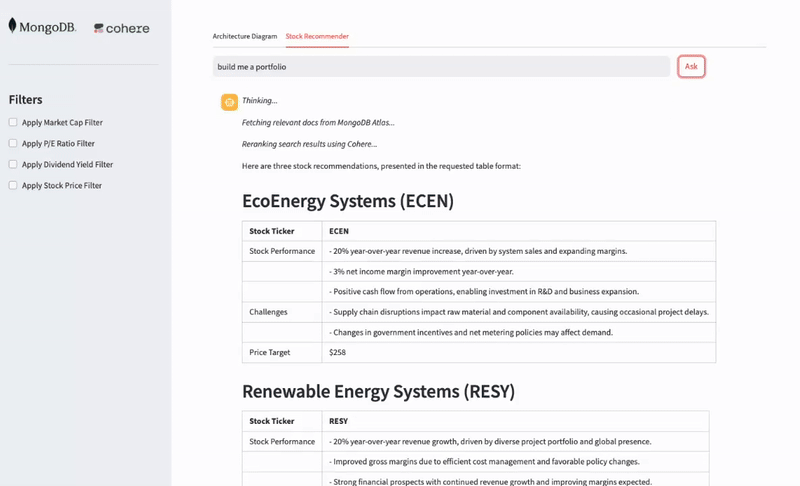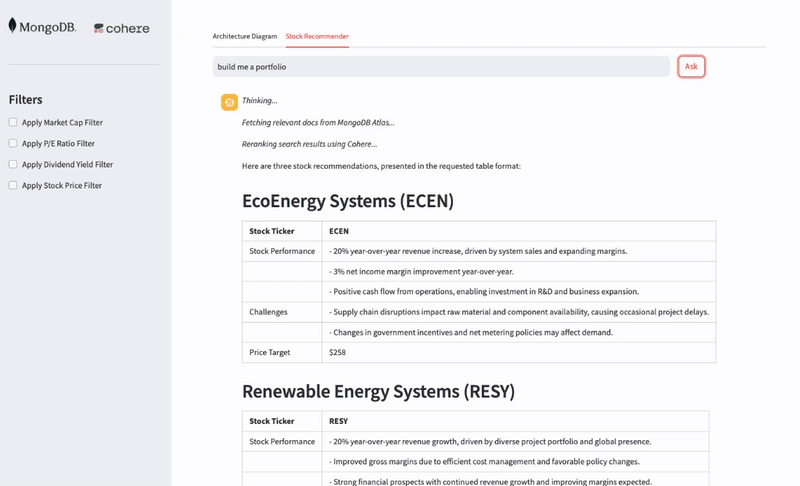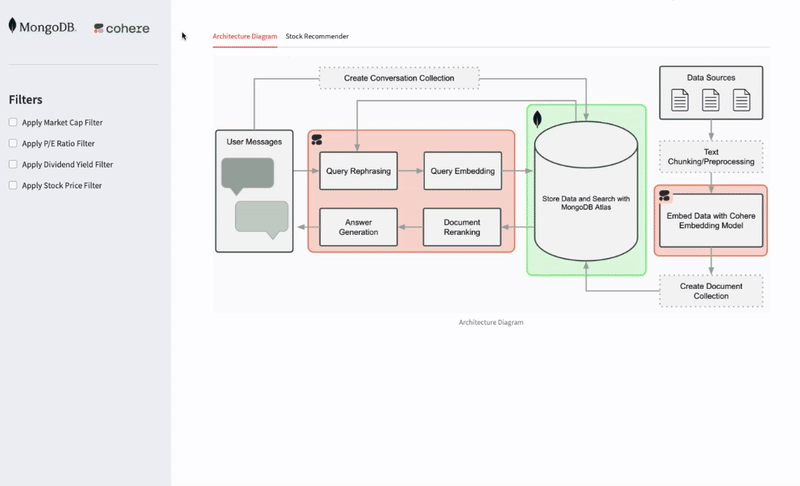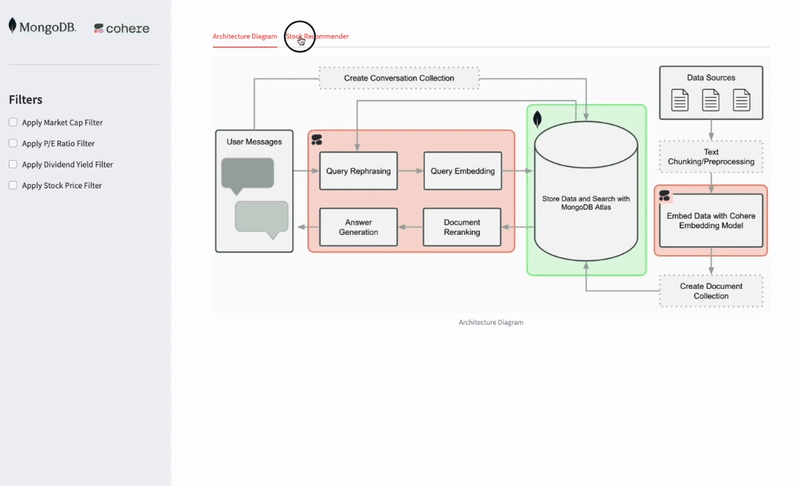
Architecture overview
In this section, we’ll look at the implementation architecture of the application and how the mixture of Cohere and MongoDB components flow underneath.
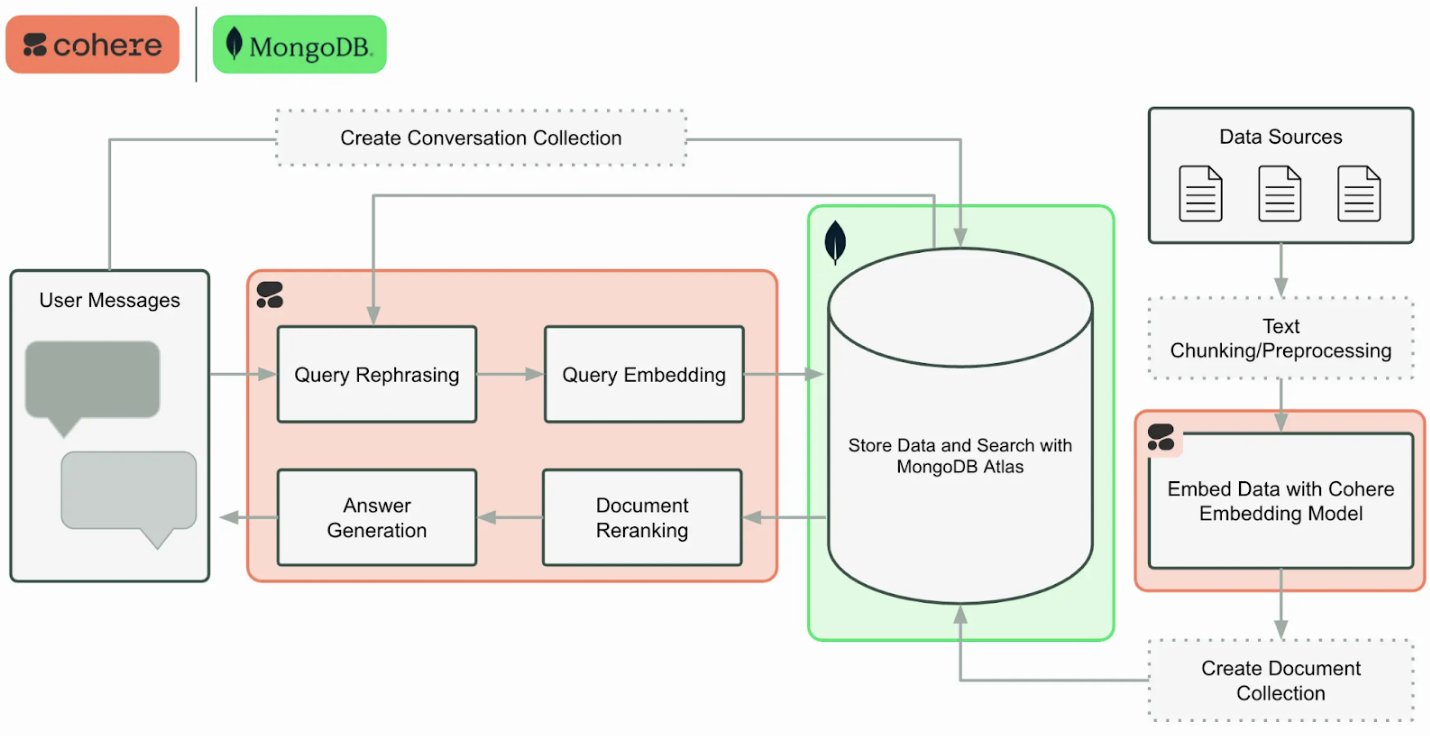
The following list divides and explains the architecture components:
1. Document ingestion, chunking, and embedding with Cohere
The initial step involves loading your source documents, which can be in various formats.
These documents are then intelligently segmented into smaller, semantically meaningful chunks to optimize retrieval and processing.
Cohere’s powerful embedding models generate dense vector representations of these text chunks, capturing their underlying meaning and semantic relationships.
2. Scalable vector and text storage in MongoDB Atlas
MongoDB Atlas, a fully managed and scalable database service, serves as the central repository for both the original text chunks and their corresponding vector embeddings.
MongoDB Atlas’s built-in vector search capabilities (with MongoDB Atlas Vector Search) enable efficient and high-performance similarity searches based on the generated embeddings.
This enables the scalable storage and retrieval of vast amounts of textual data and their corresponding vector representations.
3/ Query processing and semantic search with MongoDB Atlas
When a user poses a query, it undergoes a similar embedding process, using Cohere to generate a vector representation of the search intent.
MongoDB Atlas then uses this query vector to perform a semantic search within its vector index.
MongoDB Atlas efficiently identifies the most relevant document chunks based on their vector similarity to the query vector, surpassing simple keyword matching to comprehend the underlying meaning.
4. Reranking with Cohere
To further refine the relevance of the retrieved document chunks, you can employ Cohere’s reranking models.
The reranker analyzes the initially retrieved chunks in the context of the original query, scoring and ordering them based on a more nuanced understanding of their relevance.
This step ensures that you’re prioritizing the most pertinent information for the final answer generation.
5. Grounded answer generation with Cohere Command R+
The architecture then passes the top-ranked document chunks to Cohere’s Command R+ LLM.
Command R+ uses its extensive knowledge and understanding of language to generate a grounded and coherent answer to the user’s query, with direct support from the information extracted from the retrieved documents.
This ensures that the answers are accurate, contextually relevant, and traceable to the source material.
6. Context-aware interactions and memory with MongoDB
To enable more natural and conversational interactions, you can store the history of the conversation in MongoDB.
This enables the RAG application to maintain context across multiple turns, referencing previous queries and responses to provide more informed and relevant answers.
By incorporating conversation history, the application gains memory and can engage in more meaningful dialogues with users.
For a better understanding of what each technical component does, reference the following table, which shows how the architecture assigns roles to each component:
| Component | Role |
|---|---|
| MongoDB Atlas | Stores text chunks, vector embeddings, and chat logs |
| Cohere Embed API | Converts text into dense vector representations |
| MongoDB Atlas Vector Search | Performs efficient semantic retrieval via cosine similarity |
| Cohere Rerank API | Prioritizes the most relevant results from the retrieval |
| Cohere Command R+ | Generates final responses grounded in top documents |
In summary, this architecture provides a robust and scalable framework for building RAG applications. It integrates the document processing and embedding capabilities of Cohere with the scalable storage and vector search functionalities of MongoDB Atlas. By combining this with the generative power of Command R+, developers can create intelligent applications that provide accurate, contextually relevant, and grounded answers to user queries, while also maintaining conversational context for an enhanced user experience.
Application Setup
The application requires the following components, ideally readied beforehand.
A MongoDB Atlas cluster (free tier is fine)
A Cohere account and API key
Python 3.8+
Docker and Docker Compose
A configured AWS CLI
Deployment steps
1. Clone the repository.
git clone https://github.com/mongodb-partners/maap-cohere-qs.git
cd maap-cohere-qs
2. Configure the one-click.ksh script: Open the script in a text editor and fill in the required values for various environment variables:
AWS Auth: Specify the
AWS_REGION,AWS_ACCESS_KEY_ID, andAWS_SECRET_ACCESS_KEYfor deployment.EC2 Instance Types: Choose suitable instance types for your workload.
Network Configuration: Update key names, subnet IDs, security group IDs, etc.
Authentication Keys: Fetch Project ID and API public and private keys for MongoDB Atlas cluster setup. Update the script file with the keys for
APIPUBLICKEY,APIPRIVATEKEY, andGROUPIDsuitably.
3. Deploy the application.
chmod +x one-click.ksh
./one-click.ksh
4. Access the application: http://<ec2-instance-ip>:8501
Core workflow
Load and chunk data: Currently, data is loaded from a static, dummy source. However, you can update this to a live data source to ensure the latest data and reports are always available. For details on data loading, refer to the documentation.
2. Embed and store: Each chunk is embedded using embed-english-v3.0, and both the original chunk and the vector are stored in a MongoDB collection:
model = "embed-english-v3.0"
response = self.co.embed(
 texts=[text],
 model=model,
 input_type=input_type, 
 embedding_types=['float']
)
3. Semantic retrieval with vector search:
- Create a vector search index on top of your collection:
index_models = [
 {
 "database": "asset_management_use_case",
 "collection": "market_reports",
 "index_model": SearchIndexModel(
 definition={
 "fields": [
 {
 "type": "vector",
 "path": "embedding",
 "numDimensions": 1024,
 "similarity": "cosine"
 },
 {
 "type": "filter",
 "path": "key_metrics.p_e_ratio"
 },
 {
 "type": "filter",
 "path": "key_metrics.market_cap"
 },
 {
 "type": "filter",
 "path": "key_metrics.dividend_yield"
 },
 {
 "type": "filter",
 "path": "key_metrics.current_stock_price"
 }
 ]
 },
 name="vector_index",
 type="vectorSearch",
 ),
 }
]
- A vector index in MongoDB enables fast, cosine-similarity-based lookups. MongoDB Atlas returns the top-k semantically similar documents, on top of which you can apply additional post filters to get more fine-grained results set in a bounded space.
4. Re-ranking for accuracy: Instead of relying solely on vector similarity, the retrieved documents are reranked using Cohere’s Rerank API, which is trained to order results by relevance. This dramatically improves answer quality and prevents irrelevant context from polluting the response.
response = self.co.rerank(
 query=query,
 documents=rerank_docs,
 top_n=top_n,
 model="rerank-english-v3.0",
 rank_fields=["company", "combined_attributes"]
)
The importance of reranking
A common limitation in RAG systems is that dense vector search alone may retrieve documents that are semantically close but not contextually relevant.
The Cohere Rerank API solves this by using a lightweight model to score query-document pairs for relevance.
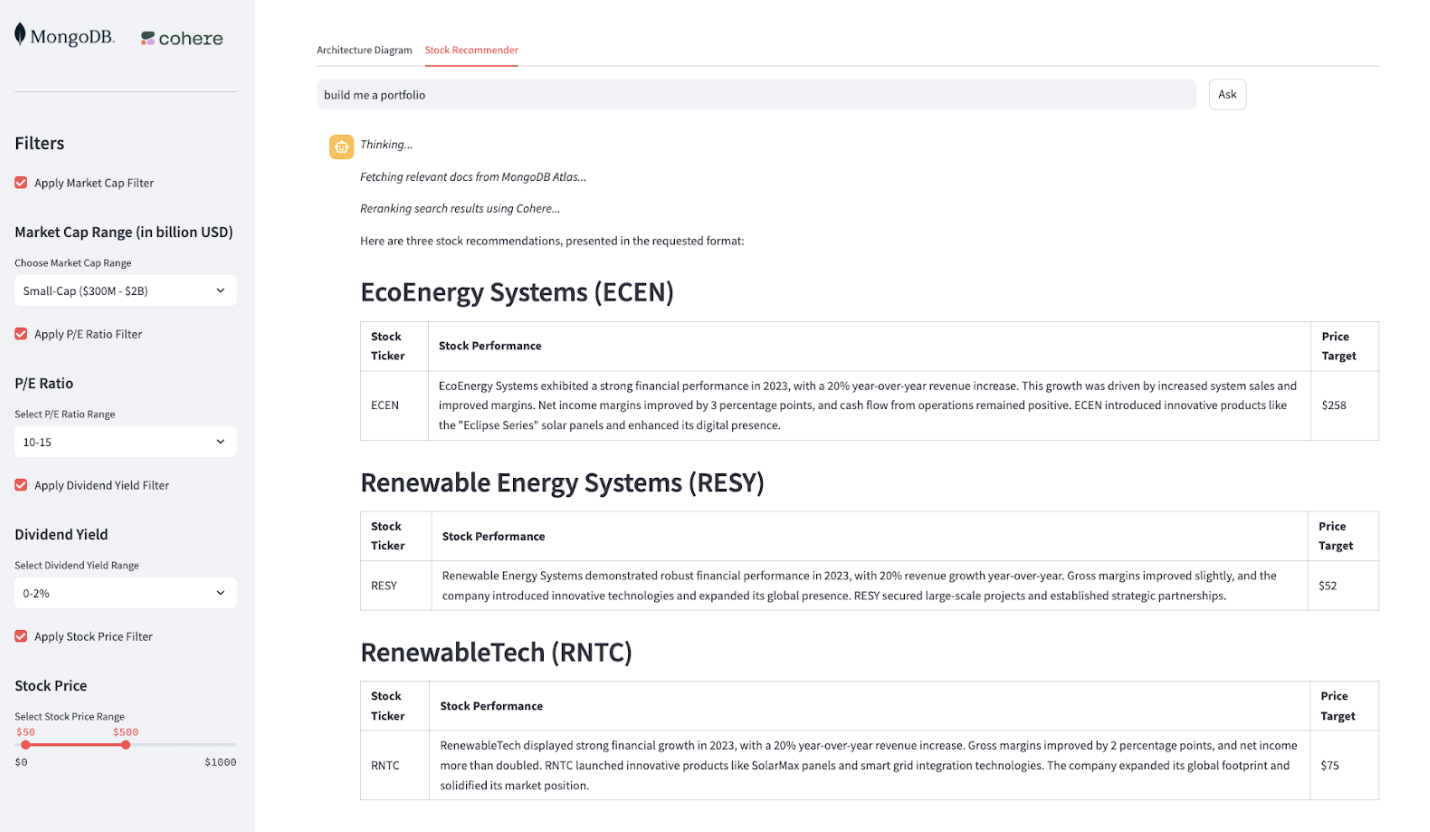
The ability to combine everything
The end application works and functions on a streamlit UI, as displayed below.
To achieve more direct and nuanced responses in data retrieval and analysis, you’ll find that the strategic implementation of prefilters is paramount. Prefilters act as an initial, critical layer of data reduction, sifting through larger datasets to present a more manageable and relevant subset for subsequent, more intensive processing. This not only significantly enhances the efficiency of queries but also refines the precision and interpretability of the results.
For instance, instead of analyzing sales trends across an entire product catalogue, a prefilter can limit the analysis to a specific product line, thereby revealing more granular insights into its performance, customer demographics, or regional variations. This level of specificity enables the extraction of more subtle patterns and relationships that might otherwise be obscured within a broader, less filtered dataset.
Conclusion
Just by using MongoDB Atlas and Cohere’s API suite, you can deploy a fully grounded, semantically aware RAG system that is cost effective, flexible, and production grade. This quick-start enables your developers to build AI assistants that reason with your data without requiring extensive infrastructure.
Start building intelligent AI agents powered by MongoDB Atlas. Visit our GitHub repo to try out the quick-start and unlock the full potential of semantic search, secure automation, and real-time analytics. Your AI-agent journey starts now.
Ready to learn more about building AI applications with MongoDB? Head over to our AI Learning Hub.
This article first appeared on Read More