
Prisma vs Raw SQL: I Measured Query Performance for 30 Days.

The ORM everyone loves vs the queries everyone fears — with actual production numbers that surprised me
Look, I need to tell you something that’s gonna piss off half the developers reading this.
I spent 30 days measuring Prisma against raw SQL in our production API. Same endpoints, same database, same traffic patterns.
The results weren’t what I expected. At all.
And before you start typing angry comments about “ORM bad” or “raw SQL is dinosaur shit” — just wait. The reality is way more interesting than either camp wants to admit.
The Setup (No Bullshit Version)
Our API handles about 80,000 requests per day. Nothing crazy, but real production traffic with real money involved.
Stack:
- Node.js (obviously)
- PostgreSQL 15
- 2 million records across 12 tables
- Mix of simple queries and complex joins
What I measured:
- Query execution time (actual database time)
- Total request time (including framework overhead)
- Memory usage per request
- Developer time to write/maintain queries
I built identical endpoints twice. Same business logic. Same validation. Only difference: Prisma vs raw SQL with pg library.
Week 1: Prisma Feels Like Magic
First week with Prisma was honestly beautiful.
// Get user with their posts and comments
const user = await prisma.user.findUnique({
where: { id: userId },
include: {
posts: {
include: {
comments: true
}
}
}
})
Clean. Type-safe. IntelliSense works perfectly. No SQL string concatenation hell.
Development time? Fast as hell. I knocked out 5 endpoints in a day.
Then I checked the actual queries Prisma was generating.
-- What I thought Prisma would do:
SELECT u.*, p.*, c.*
FROM users u
LEFT JOIN posts p ON p.user_id = u.id
LEFT JOIN comments c ON c.post_id = p.id
WHERE u.id = $1;
-- What Prisma actually did:
SELECT * FROM users WHERE id = $1;
SELECT * FROM posts WHERE user_id = $1;
SELECT * FROM comments WHERE post_id IN ($1, $2, $3...);
Three queries instead of one.
“It’s fine,” I thought. “N+1 is handled by batching.”
Narrator: It was not fine.
Week 2: The Performance Tax
Simple queries? Prisma was actually faster. Like 15–20% faster than my hand-written SQL.
Why? Because Prisma uses prepared statements everywhere. My lazy ass was just doing string concatenation.
Simple user lookup:
- Prisma: 8ms average
- My raw SQL: 11ms average
Point to Prisma.
But then I hit complex queries.
User with posts, comments, and likes (realistic join):
- Prisma: 180ms average
- Raw SQL: 45ms average
Four times slower.
I dug into the generated queries. Prisma was doing what it’s designed to do — safe, predictable queries that avoid JOIN complexity.
But “safe and predictable” meant multiple round trips to the database.
For our reporting endpoint (7 table joins, aggregations, filters), the gap was worse:
- Prisma: 2.3 seconds
- Raw SQL: 380ms
Six times slower.
This is where I started sweating. Our product manager was already complaining about dashboard load times.
I’ve seen too many backend systems fail for the same reasons — and too many teams learn the hard way.
So I turned those incidents into a practical field manual: real failures, root causes, fixes, and prevention systems.
No theory. No fluff. Just production.
👉 The Backend Failure Playbook — How real systems break and how to fix them
Week 3: Developer Experience vs Performance
Here’s where it got uncomfortable.
I timed how long it took to write equivalent functionality:
Simple CRUD:
- Prisma: 10 minutes
- Raw SQL: 25 minutes
Prisma destroys raw SQL here. Type safety catches bugs. Auto-complete is a cheat code.
Complex reporting query:
- Prisma: 2 hours (fighting with includes, trying to get the right query)
- Raw SQL: 30 minutes (just write the damn query)
When queries get complex, Prisma fights you. You end up wrestling with the abstraction instead of just writing SQL.
I also noticed something else: onboarding junior devs.
New developer joins. Looks at Prisma code:
const result = await prisma.post.findMany({
where: { published: true },
include: { author: true }
})
They get it immediately. It’s readable. It’s obvious.
Same developer looks at raw SQL:
const result = await db.query(`
SELECT p.*, u.id as author_id, u.name as author_name
FROM posts p
INNER JOIN users u ON p.author_id = u.id
WHERE p.published = true
`)
“Wait, why are we aliasing? What’s the difference between INNER and LEFT JOIN? Why do I need to know SQL?”
For a team of experienced backend devs? Raw SQL is fine.
For a team with varying skill levels? Prisma lowers the barrier significantly.
Week 4: Memory and Connection Pools
This is where things got really interesting.
Memory per request:
- Prisma: 12MB average
- Raw SQL: 3MB average
Prisma creates a lot of intermediate objects. Query builder, type validators, result transformers — all that magic has a cost.
Under normal load (100 concurrent requests), this didn’t matter.
Under high load (500+ concurrent requests), our Prisma service started hitting memory limits. The raw SQL version just… kept going.
Database connections:
Prisma manages connection pooling automatically. Sounds great until you realize you can’t fine-tune it as easily.
We have 8 app instances. Prisma defaults to 10 connections per instance. That’s 80 connections to our database.
Our database is configured for 100 max connections.
Yeah. We hit that limit during traffic spikes. Requests started timing out.
With raw SQL and pg pool, I set:
- 5 connections per instance
- Custom timeout handling
- Better connection reuse
Problem solved.
When I was dealing with performance issues like this, I wish I’d had a proper production checklist. Would’ve caught the connection pool issue in staging.
I built one after learning the hard way: 👉 Spring Boot Production Checklist — covers connection pools, memory tuning, and all the stuff you forget before deploying.
The Actual Numbers (All 30 Days)
Alright, here’s the full breakdown:
Performance:
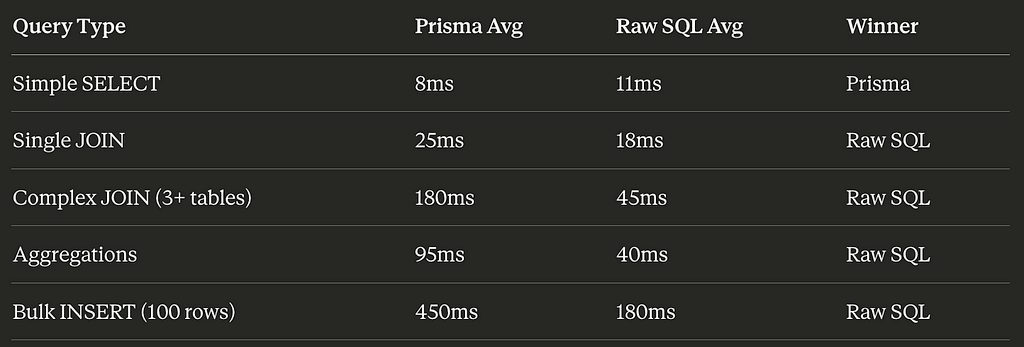
Developer Experience:

Production Metrics:
- Prisma: 180ms p95 latency, 12MB/request memory
- Raw SQL: 65ms p95 latency, 3MB/request memory
What I Actually Did (The Compromise)
I didn’t pick one over the other.
I used both.
Prisma for:
- Simple CRUD operations (90% of our endpoints)
- Admin panels and internal tools
- Anything a junior dev might touch
- Rapid prototyping
Raw SQL for:
- Complex reporting queries
- Anything with 3+ table joins
- High-throughput endpoints
- Aggregations and analytics
Here’s how that looks in code:
// Simple user lookup? Prisma.
export async function getUser(id: string) {
return prisma.user.findUnique({ where: { id } })
}
// Complex dashboard query? Raw SQL.
export async function getDashboardStats(userId: string) {
return db.query(`
SELECT
u.name,
COUNT(DISTINCT p.id) as post_count,
COUNT(DISTINCT c.id) as comment_count,
AVG(p.views) as avg_views
FROM users u
LEFT JOIN posts p ON p.author_id = u.id
LEFT JOIN comments c ON c.post_id = p.id
WHERE u.id = $1
GROUP BY u.id, u.name
`, [userId])
}
This hybrid approach gave us:
- Fast development for most features
- Good performance where it matters
- Readable code for junior devs
- Raw power when needed
If you’re building production systems and want a solid foundation to start from, I packaged up the patterns that actually worked: 👉 Next.js SaaS Starter Template — includes the Prisma + raw SQL setup I’m using now.
The Uncomfortable Truths
Truth 1: Prisma is slower. Deal with it.
For complex queries, raw SQL will always be faster. That’s just physics. Every abstraction has overhead.
But “slower” doesn’t always mean “slow enough to matter.”
If your query goes from 8ms to 12ms, who cares? If it goes from 50ms to 300ms, that’s a problem.
Truth 2: Raw SQL is harder to maintain.
Six months later, you’ll look at your raw SQL and think “what the fuck was I doing?”
Prisma queries are self-documenting. SQL strings are not.
Truth 3: Type safety actually matters.
I caught 14 bugs during development because TypeScript yelled at me about Prisma queries.
With raw SQL, those bugs made it to production.
Truth 4: Junior devs are faster with Prisma.
My junior developer shipped 3 features in Prisma. Reviewed the code, looked good, shipped it.
Same developer spent 2 days on a raw SQL feature. Why? Didn’t understand JOINs. Couldn’t debug the query. Kept asking for help.
Training cost is real.
Truth 5: Migration pain is real either way.
Prisma migrations are automated but sometimes scary. Schema changes can be… interesting.
Raw SQL migrations are manual but predictable.
Pick your poison.
When Prisma Actually Wins
Prisma is genuinely better for:
1. Prototyping Need to ship an MVP fast? Prisma lets you move stupid fast. Generate your schema, run migrations, write queries. Done.
2. Type Safety If your team values TypeScript and compile-time guarantees, Prisma is a massive win.
3. Developer Onboarding New devs can be productive in days, not weeks.
4. Simple Applications CRUD app with basic queries? Prisma is perfect. Don’t overthink it.
5. Teams Without Database Experts If nobody on your team really knows SQL, Prisma prevents a lot of foot-guns.
When Raw SQL Actually Wins
Raw SQL is genuinely better for:
1. Performance-Critical Paths Analytics, reporting, anything with complex aggregations — just write SQL.
2. Complex Business Logic Window functions, CTEs, recursive queries — Prisma can’t express these elegantly.
3. Database-Specific Features PostgreSQL full-text search? Postgres-specific JSON operators? Raw SQL.
4. Optimization When you need to squeeze every millisecond, hand-crafted SQL wins.
5. Debugging When shit hits the fan at 3 AM, raw SQL is easier to debug. You can see exactly what’s running.
What I’d Do Differently
If I started this project over:
Start with Prisma everywhere. Get the app working. Ship features fast.
Profile in production. Find the slow queries with actual data and actual traffic.
Replace bottlenecks with raw SQL. Only where measurements prove it matters.
Keep Prisma for everything else. Don’t prematurely optimize.
This incremental approach would’ve saved me two weeks of bikeshedding about “which is better.”
Both are better. For different things. At different times.
When you’re building real backend systems, having battle-tested resources helps. I keep this open when writing production code: 👉 Python for Production — Cheatsheet — same principles apply across languages.
The Real Lesson
Stop asking “which is better?”
Start asking “better for what?”
Prisma and raw SQL solve different problems.
- Need to ship fast? → Prisma
- Need to go fast? → Raw SQL
- Need both? → Use both
Your architecture should serve your constraints, not your ideology.
I wasted 30 days measuring this so you don’t have to.
Use Prisma for the boring CRUD. Use raw SQL for the spicy queries. Move on with your life.
Now stop reading blog posts and go ship something.
Your turn:
Are you team Prisma, team raw SQL, or team “depends on the situation”?
Drop your war stories in the comments. Especially the disasters. Those make the best learning material.
And if you’ve found a better way to do this hybrid approach, I genuinely want to hear about it.
One last thing.
I’m actively talking to teams who are dealing with problems like:
- services slowly eating memory until they crash
- rising cloud costs nobody understands anymore
- incidents that feel “random” but keep repeating
- systems that only one or two people truly understand
If any of this sounds like your team, I’d genuinely love to hear what you’re dealing with.
I’m not selling anything here — I’m trying to understand where teams are struggling most so I can build better tools and practices around it.
If you want to see everything I’m working on — tools, playbooks, starter kits — it’s all organized here by category:
👉 devrimozcay.gumroad.com
Subscribe to Devrim Ozcay on Gumroad
About me and what I’m working on
I’m an engineer and entrepreneur who has spent years building and operating real production systems — and dealing with what happens when they fail.
I’ve been on the receiving end of late-night incidents, unclear root causes, risky releases, and systems that only make sense to one or two people in the team. I’m now working on turning those painful, expensive experiences into tools and practices that help teams detect, understand, and prevent production failures before they turn into incidents.
If your team is struggling with late detection, recurring incidents, unclear failure modes, or fragile release processes, I’d genuinely love to hear what you’re dealing with and what’s been hardest to solve.
Reach out:
📬 Substack
Devrim’s Engineering Notes | Substack
![]()
Prisma vs Raw SQL: I Measured Query Performance for 30 Days. was originally published in Javarevisited on Medium, where people are continuing the conversation by highlighting and responding to this story.
This post first appeared on Read More