
Building Prometheus: How Backend Aggregation Enables Gigawatt-Scale AI Clusters
- We’re sharing details of the role backend aggregation (BAG) plays in building Meta’s gigawatt-scale AI clusters like Prometheus.
- BAG allows us to seamlessly connect thousands of GPUs across multiple data centers and regions.
- Our BAG implementation is connecting two different network fabrics – Disaggregated Schedule Fabric (DSF) and Non-Scheduled Fabric (NSF).
Once it’s complete our AI cluster, Prometheus, will deliver 1-gigawatt of capacity to enhance and enable new and existing AI experiences across Meta products. Prometheus’ infrastructure will span several data center buildings in a single larger region, interconnecting tens of thousands of GPUs.
A key piece of scaling and connecting this infrastructure is backend aggregation (BAG), which we use to seamlessly connect GPUs and data centers with robust, high-capacity networking. By leveraging modular hardware, advanced routing, and resilient topologies, BAG ensures both performance and reliability at unprecedented scale
As our AI clusters continue to grow, we expect BAG to play an important role in meeting future demands and driving innovation across Meta’s global network.
What Is Backend Aggregation?
BAG is a centralized Ethernet-based super spine network layer that primarily functions to interconnect multiple spine layer fabrics across various data centers and regions within large clusters. Within Prometheus, for example, the BAG layer serves as the aggregation point between regional networks and Meta’s backbone, enabling the creation of mega AI clusters. BAG is designed to support immense bandwidth needs, with inter-BAG capacities reaching the petabit range (e.g., 16-48 Pbps per region pair).
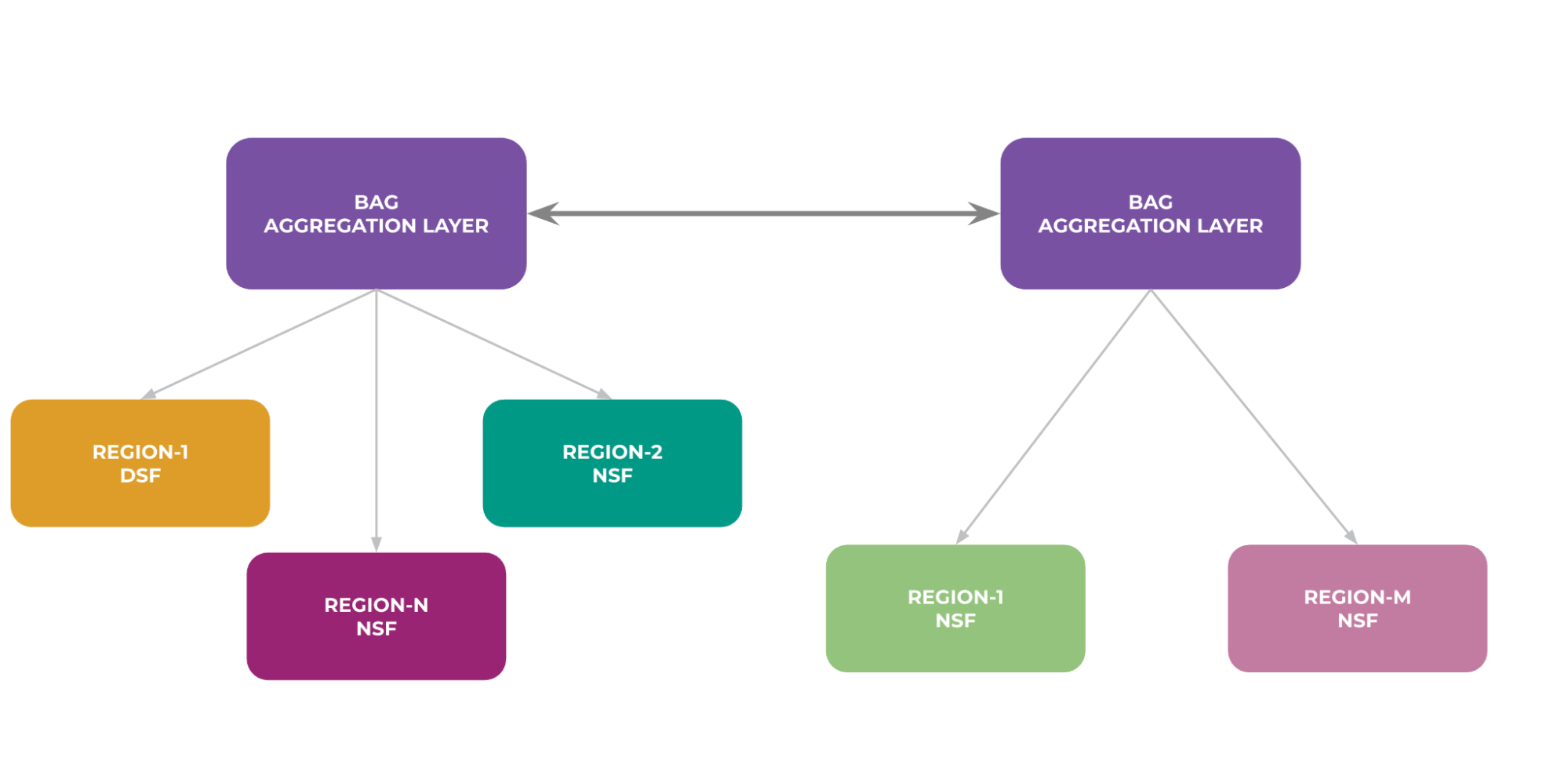
How BAG Is Helping Us Build Gigawatt-Scale AI Clusters
To address the challenge of interconnecting tens of thousands of GPUs, we’re deploying distributed BAG layers regionally.
How We Interconnect BAG Layers
BAG layers are strategically distributed across regions to serve subsets of L2 fabrics, adhering to distance, buffer, and latency constraints. Inter-BAG connectivity utilizes either a planar (direct match) or spread connection topology, chosen based on site size and fiber availability.
- Planar topology connects BAG switches one-to-one between regions following the plane, offering simplified management but concentrating potential failure domains.
- Spread connection topology distributes links across multiple BAG switches/planes, enhancing path diversity and resilience.
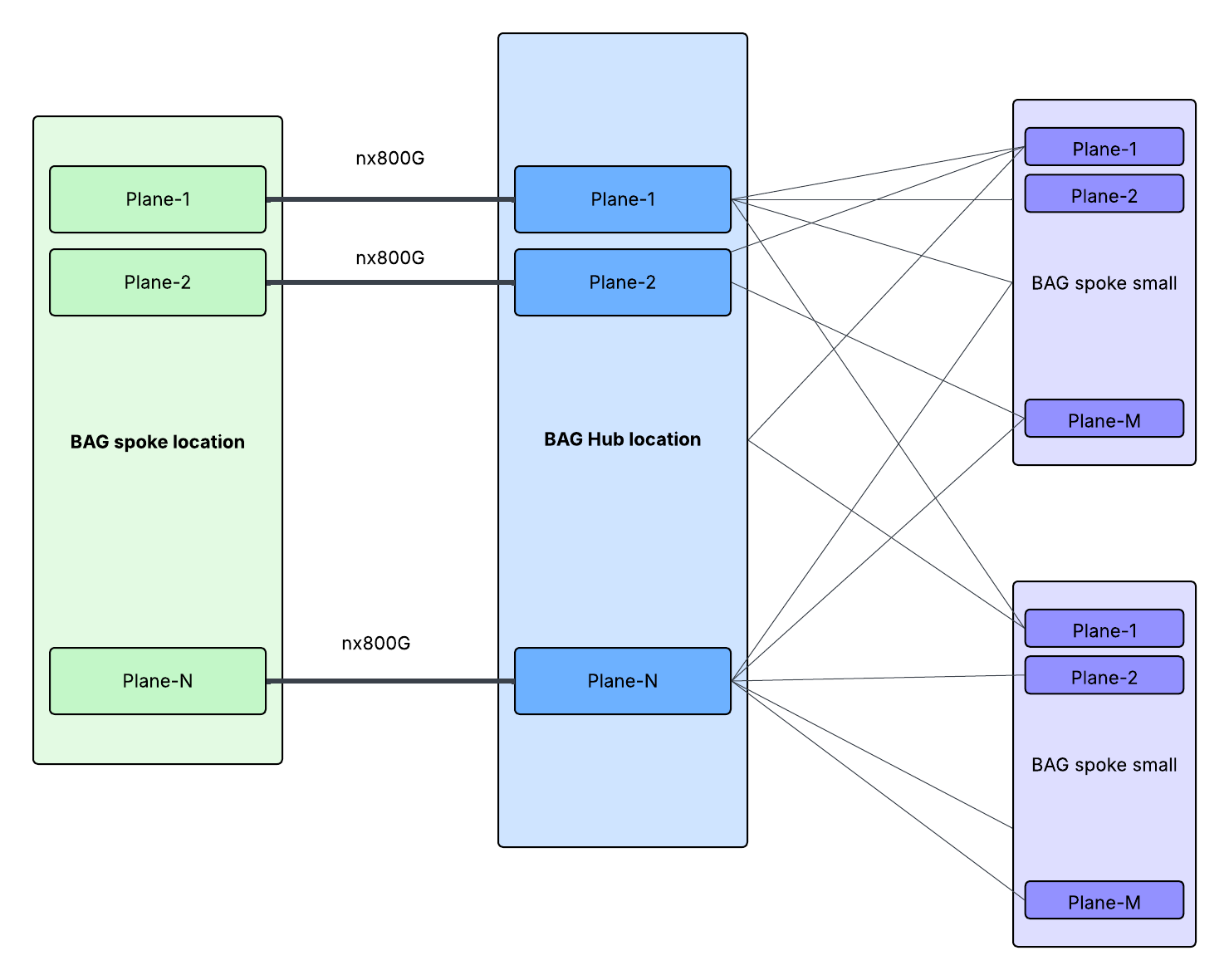
How a BAG Layer Connects to L2 Fabrics
So far, we’ve discussed how the BAG layers are interconnected, now let’s see how a BAG layer connects downstream to L2 fabrics.
We’ve used two main fabric technologies, Disaggregated Schedule Fabric (DSF) and Non-Scheduled Fabric (NSF) to build L2 networks.
Below is an example of DSF L2 zones across five data center buildings connected to the BAG layer via a special backend edge pod in each building.

Below is an example of NSF L2 connected to BAG planes. Each BAG plane connects to matching Spine Training Switches (STSWs) from all spine planes. Effective oversubscription is 4.98:1.
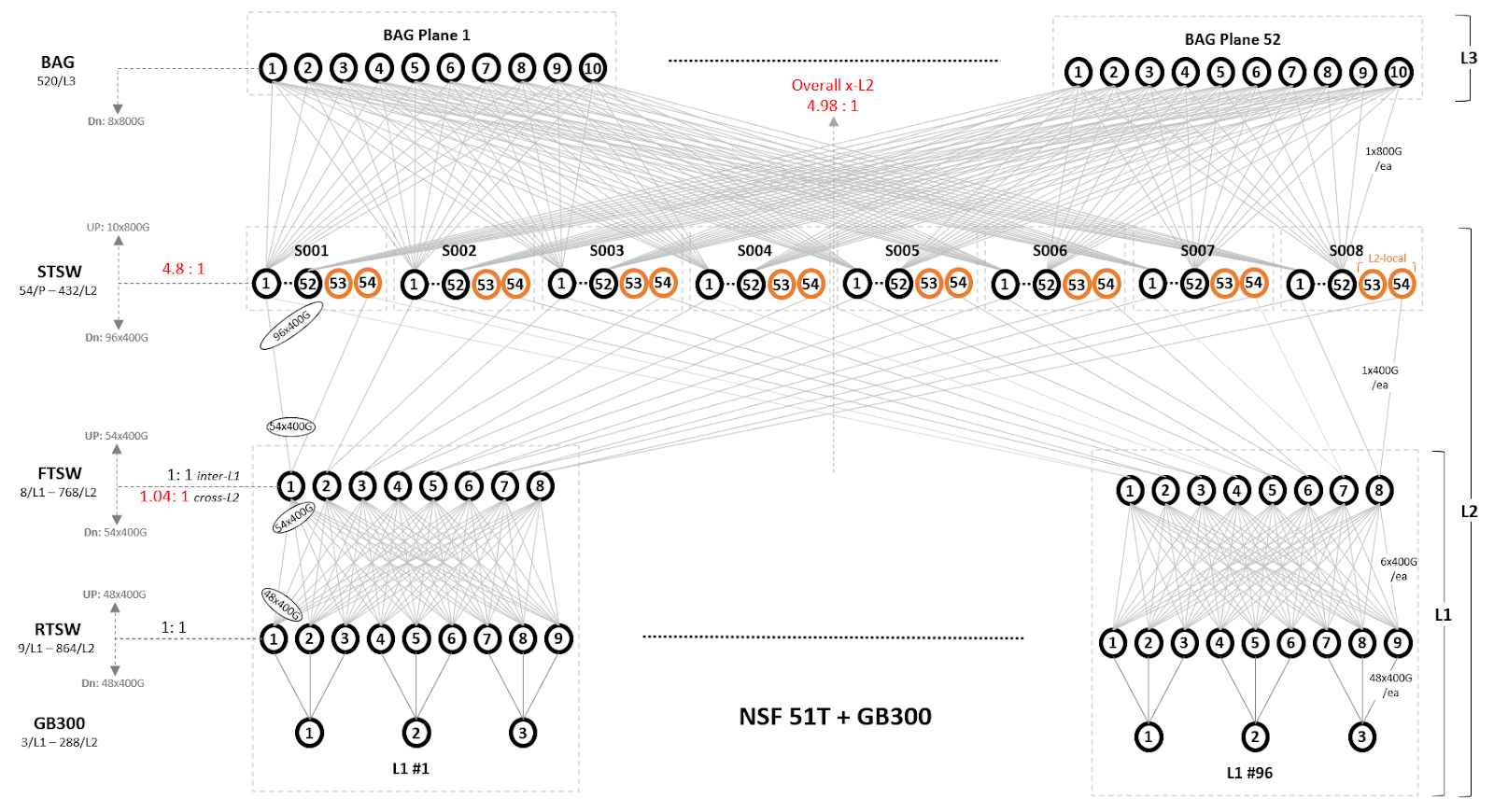
Careful management of oversubscription ratios assists in balancing scale and performance. Typical oversubscription from L2 to BAG is around 4.5:1, while BAG-to-BAG oversubscription varies based on regional requirements and link capacity.
Hardware and Routing
Meta’s implementation of BAG uses a modular chassis equipped with Jericho3 (J3) ASIC line cards, each providing up to 432x800G ports for high-capacity, scalable, and resilient interconnect. The central hub BAG employs a larger chassis to accommodate numerous spokes and long-distance links with varied cable lengths for optimized buffer utilization.
Routing within BAG uses eBGP with link bandwidth attributes, enabling Unequal Cost Multipath (UCMP) for efficient load balancing and robust failure handling. BAG-to-BAG connections are secured with MACsec, aligning with network security requirements.
Designing the Network for Resilience
The network design meticulously details port striping, IP addressing schemes, and comprehensive failure domain analysis to ensure high availability and minimize the impact of failures. Failure modes are analyzed at the BAG, data hall, and power distribution levels. We also employ various strategies to mitigate blackholing risks, including draining affected BAG planes and conditional route aggregation.
Considerations for Long Cable Distances
An important advantage of BAG’s distributed architecture is it keeps the distance from the L2 edge small, which is important for shallow buffer NSF switches. Longer, BAG-to-BAG, cable distances dictate that we use deep buffer switches for the BAG role. This provides a large headroom buffer to support lossless congestion control protocols like PFC.
Building Prometheus and Beyond
As a technology, BAG is playing an important role in Meta’s next generation of AI infrastructure. By centralizing the interconnection of regional networks, BAG helps enable the gigawatt-scale Prometheus cluster, ensuring seamless, high-capacity networking across tens of thousands of GPUs. This thoughtful design, leveraging modular hardware and resilient topologies, positions BAG to not only meet the demands of Prometheus but also to drive the future innovation and scalability of Meta’s global AI network for years to come.
The post Building Prometheus: How Backend Aggregation Enables Gigawatt-Scale AI Clusters appeared first on Engineering at Meta.
This post first appeared on Read More