
llamafile Reloaded: What’s New in v0.10.0

We are happy to announce the release of llamafile 0.10.0.
Since our previous announcement, we’ve rebuilt llamafile from the ground up, following an approach that makes it far easier to keep pace with its upstream dependencies.
We started with a polyglot build of llama.cpp, so we could get the best of two worlds. On one side, the signature features that make llamafile what it is: portability across different systems and CPU architectures, plus the ability to bundle model weights directly into llamafile executables. On the other side, all the features and model support available in the latest versions of llama.cpp, so that now you can serve Qwen3.5 models for vision, lfm2 for tool calling, and use Anthropic Messages API to run Claude code with a local model, all of this by running a single executable file.
What can the new llamafile do?
We asked for your feedback and we hear you: what makes a llamafile isn’t just an APE executable. So we’ve brought back more of llamafile’s original features. Here’s what you’ll find in 0.10.0:
- APE executable running out-of-the-box on multiple OSes and CPU architectures
- Full llama.cpp server feature set, including recent models, multimodal support, tool calling, and the Anthropic Messages API
- Multimodal model support in the terminal chat
- Multiple UIs: CLI tool, HTTP server, and terminal chat interface
- Metal GPU support
- CUDA GPU support (currently tested on Linux)
- CPU optimizations for different architectures
- Whisperfile
Where can I get a llamafile?
We provide a few pre-built llamafiles for you to try here. We’ve selected a variety of models covering different capabilities (thinking, multimodal, tool calling) and sizes ranging from 0.6B to 27B parameters. But we don’t want to be a bottleneck to your creativity, so we want you to experiment with different models and configurations!
If you already have model weights on your system, you can just download the main llamafile executable and load your GGUF files directly. The v0.10.0 llamafile and whisperfile executables are available here. Check out our documentation to see how to run them with pre-downloaded models. And if you are looking for an easier way to bundle your own llamafiles, here’s a teaser image from llamafile-builder, an application we are building with this specific goal:
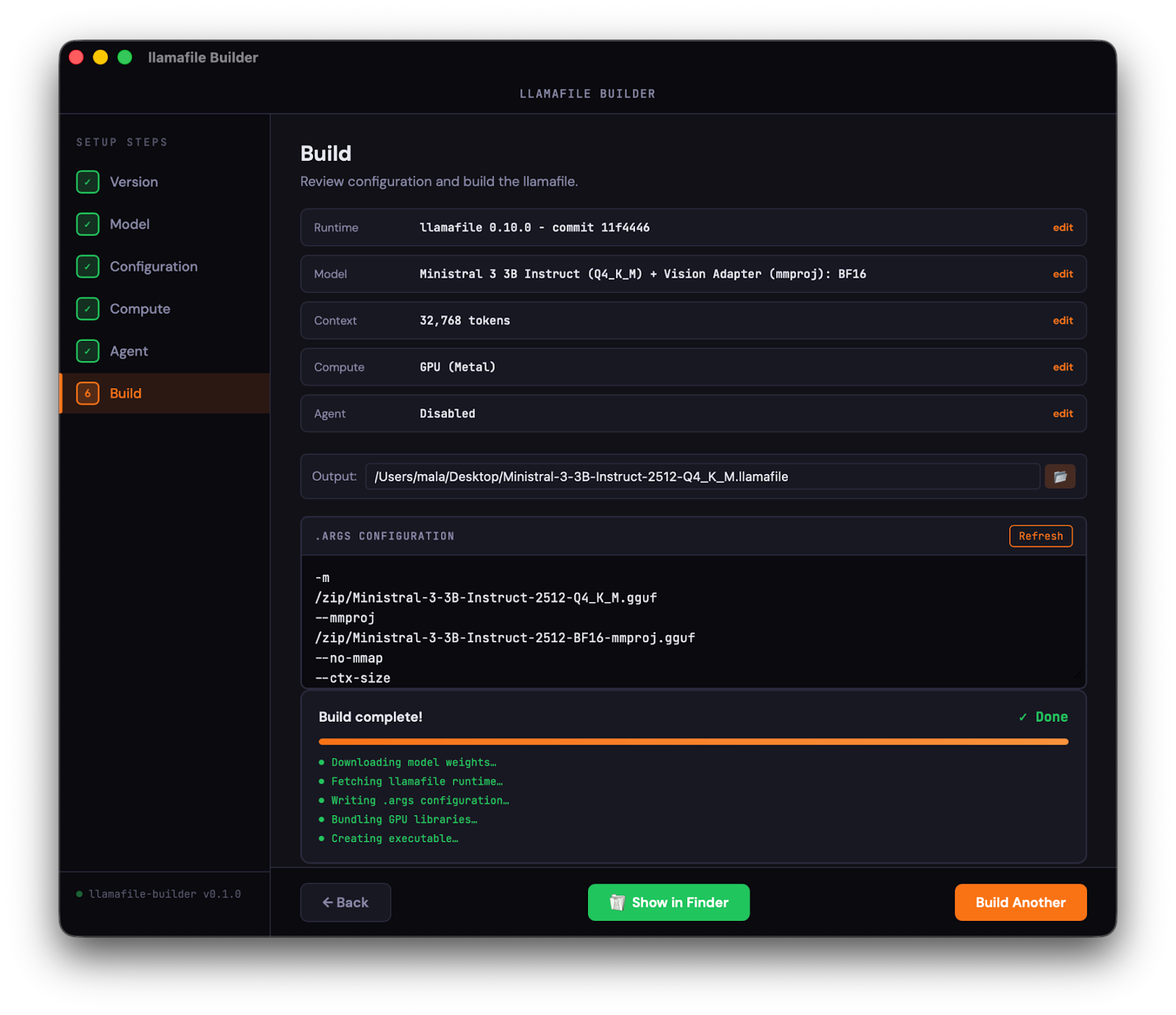
What next?
We have plenty of ideas for the future llamafile. Here’s what we’re currently working on:
- Feature parity with the older version of llamafile. We documented here some of the features we haven’t caught up with yet. Let us know what you’d like prioritized!
- Easier bundling (see the teaser above): we want to see you experimenting with combinations of models and parameters we never thought of, and sharing them around!
- Vulkan support: check out one more teaser we left for you at the end of this post.
- And of course, finding and fixing any new issues we can spot. 🙂
What about the old llamafile?
If there’s something you’re missing from the old llamafile:
- Let us know! We want to build something that’s useful for you.
- Check out previous builds: you can still download source code from older commits and binaries from previous releases.
- Look for older llamafiles: we’re still hosting a wide range of older models on HuggingFace, and for each one we specify the llamafile version it was built with.
- Build your own: we’ll be making it easier for you to build llamafiles with whatever version of the software you want.
… And last but not least, if you need another good reason to try the newer llamafiles:
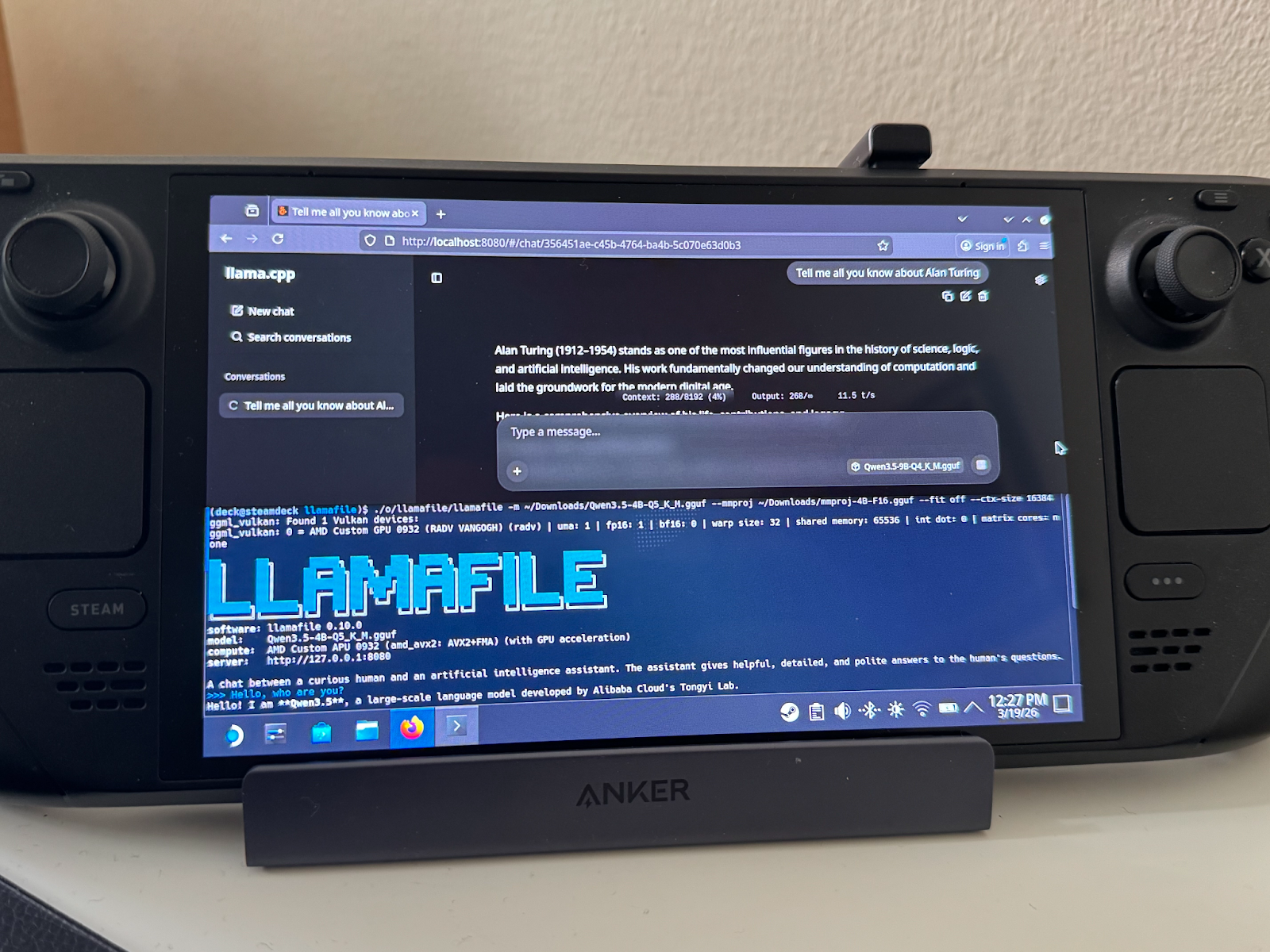
This article first appeared on Read More