
Escaping the Fork: How Meta Modernized WebRTC Across 50+ Use Cases
- At Meta, WebRTC powers real-time audio and video across various platforms. But forking a large open-source project like WebRTC within our monorepo presents unique challenges – over time, an internal fork can drift behind upstream, cutting itself off from community upgrades.
- We’re sharing how we escaped this “forking trap” – from building a dual-stack architecture that enabled safe A/B testing across 50+ use cases, to the workflows that now keep us continuously upgraded with upstream.
- This approach improved performance, binary size, and security – and we continue to use it today to A/B test each new upstream release before rolling it out.
At Meta, real-time communication (RTC) powers various services from global Messenger and Instagram video chats to low-latency Cloud Gaming and immersive VR casting on Meta Quest. To meet the performance demands of billions of users, we spent years developing a specialized, high-performance variant of the open-source WebRTC library.
Permanently forking a big open-source project can result in a common industry trap. It starts with good intentions: You need a specific internal optimization or a quick bug fix. But over time, as the upstream project evolves and your internal features accumulate, the resources needed to merge in external commits can become prohibitive.
Recently, we officially concluded a massive multiyear migration to break this cycle. We successfully moved over 50 use cases from a divergent WebRTC fork to a modular architecture built on top of the latest upstream version – using it as a skeleton while injecting our own proprietary implementations of key components.
This article details how we engineered a solution to solve the “forking trap,” allowing us to build two versions of WebRTC simultaneously within a single library for the sake of A/B testing, while living in a monorepo environment, with continuous upgrade cycles of the library that’s being tested.
The Challenge: The Monorepo and the Static Linker
Upgrading a library like WebRTC can be risky, especially when upgrading while serving billions of users and introducing regressions that are hard to rollback. This also eliminates the possibility of a one-time upgrade, which could break some users’ experiences due to the variety of devices and environments we are running at.
To mitigate this, we prioritized A/B testing capabilities in order to run the legacy version of WebRTC alongside the new upstream version with clean patches and apply our features in the same app while being able to dynamically switch users between them to verify the new version.
Due to application build graph and size constraints, we also prioritized finding a solution to statically link two WebRTC versions. However, this violates the C++ linker One Definition Rule (ODR), causing thousands of symbol collisions, so we turned to finding a way to make two versions of the same library coexist in the same address space.
Furthermore, Meta is using a monorepo and we don’t want to undergo the same process over and over again. This motivated us to find a solution to maintain custom patches for open-source projects in a monorepo environment, while being able to pull new versions from upstream and apply the patches over and over again.
This led us to focus on solving two challenges:
- We desired A/B testing capability. To achieve that, we built two copies of WebRTC in the same library due to application constraints.
- With no feature branches in monorepo, how do we track patches and rebase them? Other libwebrtc-based OSS projects usually do this by applying a set of stored patch files sequentially on top of the clean repo on each library upgrade. Due to scalability concerns, we explored more nuanced options.
Solution 1: The Shim Layer and Dual-Stack Architecture
To address the A/B testing capability, we chose to build two copies of WebRTC within the same app. However, doing this statically within the same overarching call orchestration library creates unique challenges. To tackle this, we built a shim layer between the application layer and WebRTC. It is a proxy library that sits between our application code and the underlying WebRTC implementations. Instead of the app calling WebRTC directly, it calls the shim API. The shim exposes a single, unified, version-agnostic API.
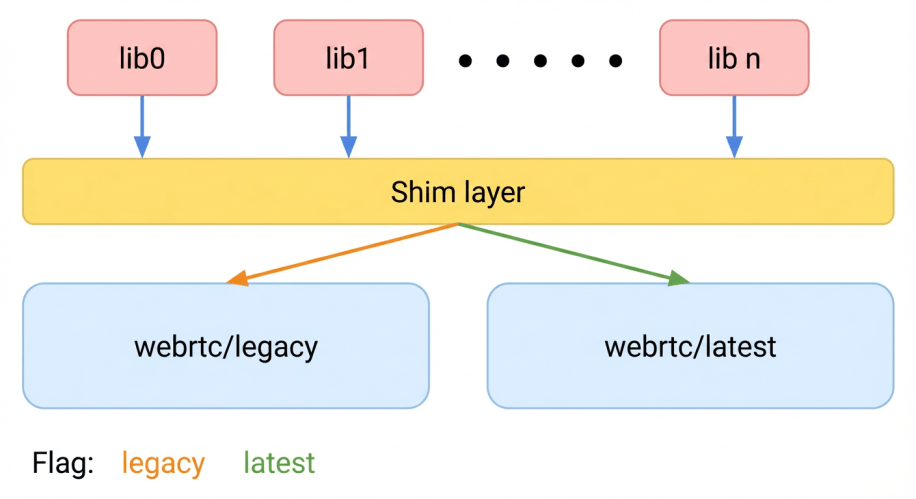
The shim layer holds a “flavor” configuration and dispatches each call to either the legacy or latest WebRTC implementation at runtime. This approach – shimming at the lowest possible layer – avoids a significant binary size regression that duplicating the higher-layer call orchestration library would have caused. Duplication would have resulted in an uncompressed size increase of approximately 38 MB, whereas our solution added only about 5 MB – an 87% reduction.
Next, we’ll look at the hurdles introduced by this dual-stack architecture and how we resolved them.
Solving Symbol Collisions
Statically linking two copies of WebRTC into a single binary produces thousands of duplicate symbol errors.
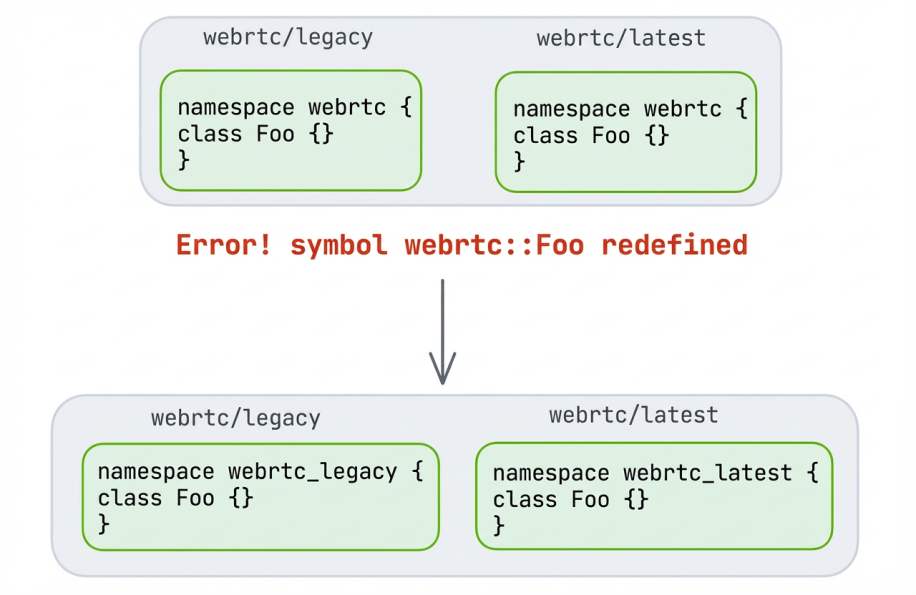
In order to ensure every symbol in each flavor is unique, we leveraged automated renamespacing: We built scripts that systematically rewrite every C++ namespace in a given WebRTC version, so the webrtc:: namespace in the latest upstream copy becomes webrtc_latest::, while the legacy copy becomes webrtc_legacy::. This rename was applied to every external namespace in the library.
But not everything in WebRTC lives in a namespace – global C functions, free variables, and classes that were left outside namespaces intentionally or accidentally also collide.
For those, we moved what we could into namespaces and manipulated the symbols of the rest (like global C functions) with flavor-specific identifiers.
Macros and preprocessor flags presented a subtler problem. Macros like RTC_CHECK and RTC_LOG can be used outside of WebRTC in wrapper libraries, so including both versions’ headers in the same translation unit triggers redefinition errors.
We addressed this through a combination of strategies:
- Removing spurious includes.
- Renaming rarely-used macros.
- Sharing internal WebRTC modules across versions where possible, like rtc_base. This last approach had the added benefit of reducing both binary size and the surface area of code that needed shimming.
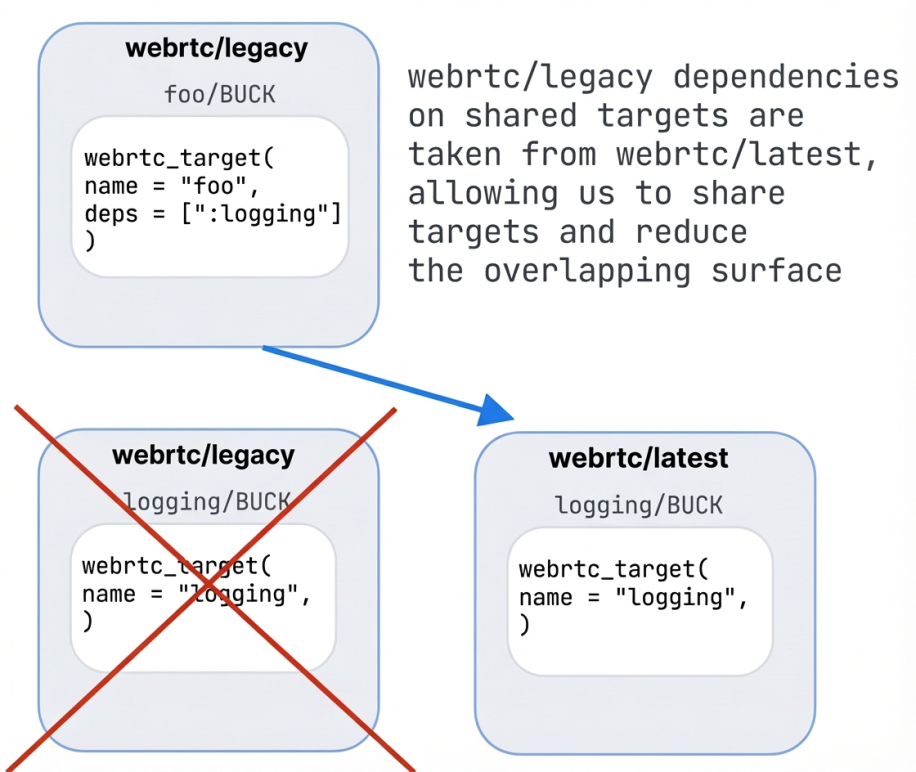
Backward Compatibility
Renamespacing every symbol in WebRTC would break every external call site. Our focus was to keep existing code working without disruption. Some call sites are built with a constant WebRTC flavor, and not dual-stack.
Our initial approach was to forward-declare every used symbol from the new namespace and wire it to the old one. This worked, but produced a large fragile header file that required a high level of maintenance.
We iterated to a better solution: bulk namespace imports using C++ using declarations. By importing an entire flavor namespace into the familiar webrtc:: namespace, we achieved a concise declaration header where new symbols are handled automatically, with no binary size implications since these are pure compiler directives. External engineers continue writing code exactly as before – the wiring happens in parallel, where we migrate only external call sites we care about.
Flavoring: Runtime Version Dispatch
With the shim layer wrapping both WebRTC versions, the next question was: How do we dispatch to the correct version at runtime? Each adapter and converter needs to instantiate the right underlying object – webrtc_legacy:: or webrtc_latest::, based on a global configuration flag.
We addressed this with a template-based helper library. Shared logic (which constitutes a large portion of the adapter code) is written once. Version-specific behavior is expressed through C++ template specializations. This keeps the code DRY while supporting backward compatibility with single-flavor builds during the transition period. A global flavor enum, set early in each app’s startup sequence, determines which flavor to activate.
We use directional adapters as intermediary objects that implement the unified API and dispatch to the underlying WebRTC object, or vice versa. We use directional converters as utility functions to translate structs and enums between the shim and WebRTC type systems.

Shim Generation
The shim layer itself required adapters and converters. With a large number of objects to shim across dozens of APIs – each requiring an abstract API definition, adapter and converters implementations, and unit tests – the estimated manual effort was huge!
We turned to automation. Using abstract syntax tree (AST) parsing, we built a code generation system that produces baseline shim code for classes, structs, enums, and constants. The generated code is fully unit-tested and easy to extend. This increased our velocity from one shim per day to three or four per day while reducing the risk of human error. For simple shims where the API is identical across versions, the generated code required close to zero manual intervention. For more complex cases – API discrepancies between versions, factory patterns, static methods, raw pointer semantics, and object ownership transfers – engineers refined the generated baseline.
Wiring and Building Dual-Stack Apps
With the shim layer in place, we began the painstaking work of rewiring all application references from direct WebRTC types to their shim equivalents. For example, webrtc::Foo became webrtc_shim::Foo. This introduced object ownership complexities and the potential for subtle bugs around null handling and memory management. We mitigated this through comprehensive unit testing that replicated problematic scenarios of ownership transfer and object lifetime, supplemented by end-to-end testing for particularly risky diffs.
We then worked iteratively toward building full apps in dual-stack mode, starting with small targets and working up. Each iteration surfaced new issues: missing shims, incorrectly flavored objects, and new macro or symbol collisions.
Some internal components that were injected into WebRTC from outside posed a particular challenge due to their deep dependencies on WebRTC internals. Since shimming these components would mean proxying WebRTC against itself, we instead “duplicated” them using C++ macro and Buck build machinery – dynamically changing namespaces at build time, duplicating the high-level build target, and exposing symbols for both flavors through a single header.
Once finished, we had our internal app, as well as some external applications, all building and running audio and video calls in dual-stack mode for both legacy and latest flavors.
Over 10,000 lines of shim code were added, and hundreds of thousands of lines were modified across thousands of files. Despite the scope, careful testing and review meant no major issues.
Using this approach, we were able to A/B test the legacy WebRTC release against the latest one, app-by-app, mitigate regressions, ship, and delete the legacy code. Today, the shim approach is used in some applications so we can continuously upgrade the internal WebRTC code with the latest upstream updates.
Solution 2: The Feature Branches
Since we use a monorepo without widespread support for branches, we sought a way to track patches over time that would be continuously rebased on top of upstream. Our clear requirement was that each patch would have a clearly delineated purpose and owning team.
We had two choices here: We could track patch files checked into source control and reapply them one by one in the correct order, or we could track patches in a separate repository that supported branching.
In the end we chose to go with tracking feature branches in a separate Git repository. One of the reasons for this was to establish a good pipeline for making it very easy to submit feature branches and fixes upstream.
By basing them on top of the libwebrtc Git repo, we could easily reuse existing upstream Chromium tools for building, testing, and submitting (`gn`, `gclient`, `git cl`, and more).
For each upstream Chromium release (such as M143 which has tag 7499 in git), we create a “base/7499” branch. Then, for each of our patches (e.g. “debug-tools”) we create a “debug-tools/7499” branch on top of the base/7499 commit. During a version upgrade, we merge forward all feature branches, debug-tools/7499 gets merged into debug-tools/7559, hw-av1-fixes/7499 into hw-av1-fixes/7599, and so on.
Once all features are merged forward with resolved conflicts and working builds + tests, we merge all the feature branches sequentially together to create the release candidate branch r7559.
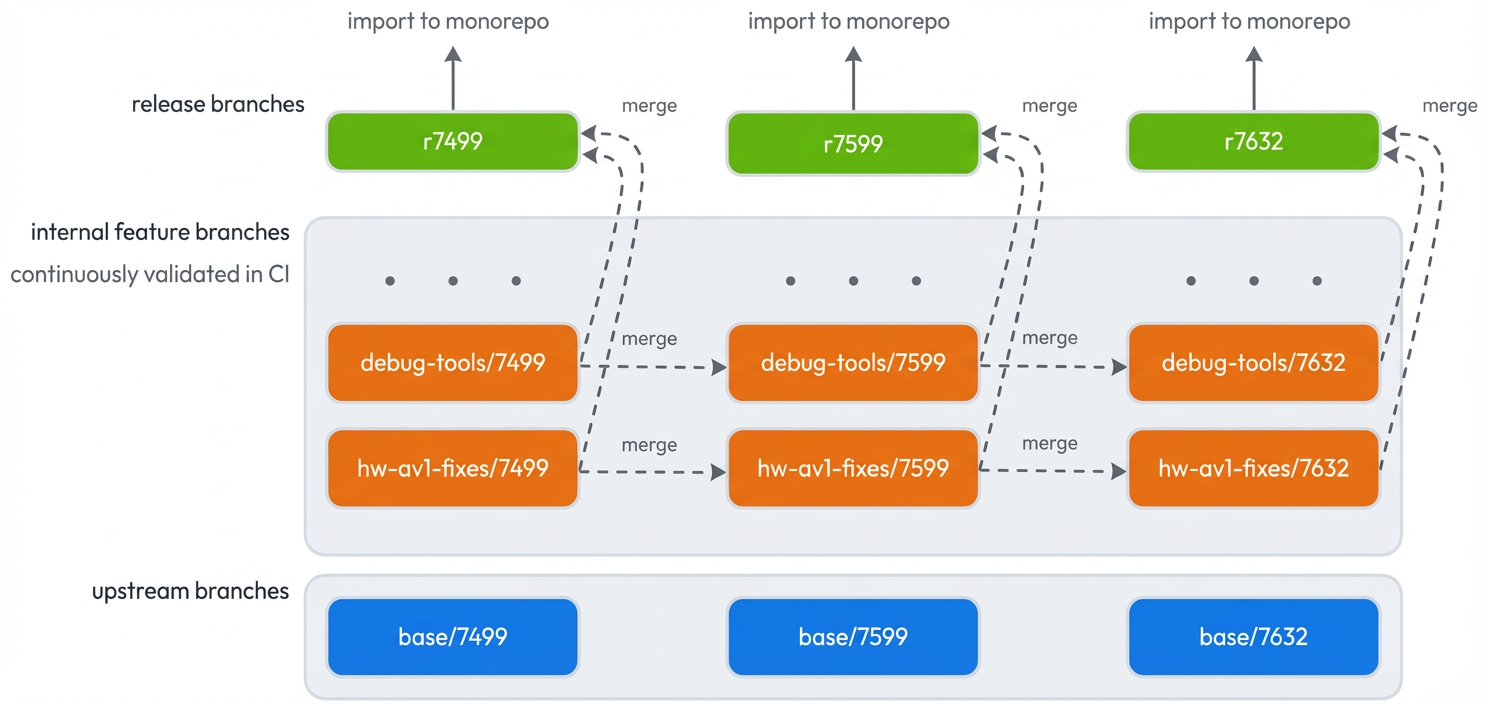
Some nice benefits from this approach are that it is highly parallelizable if there are many branches, it automatically preserves all Git history/context, and it is well-suited for future improvements in LLM-driven auto-resolution of merge conflicts. Additionally, the feature branches make it easy to submit the branch as a whole as an upstream contribution into OSS.
The Result: Continuous Upgrades
This architecture allowed us to ship a binary containing both the old and new WebRTC stacks. We launched webrtc/latest on version M120 and have since progressed to M145. Instead of being years behind, we now stay current with the latest stable Chromium releases, ingesting upstream upgrades immediately.
Key Engineering Wins
- Performance: We saw CPU usage drop by up to 10% and crash rates improve by up to 3% across major apps.
- Binary Size: The new upstream version is more efficient, resulting in a 100-200 KB (compressed) size reduction depending on the app.
- Security: We eliminated deprecated libraries (like usrsctp) and fixed security vulnerabilities present in the legacy stack.
- All the above drove observable user engagement improvements while running on a modern stack.
This project proves that even in a complex monorepo environment with various constraints, it is possible to modernize technical debt without a complete rewrite. The shim layer with dual-stack approach offers a blueprint for any organization looking to escape the forking trap.
Future Work: AI-Driven Maintenance
With the migration complete, we are entering a new era of maintenance. While we are now “living at head,” we still apply internal patches on top of upstream. To manage this efficiently, we are leveraging tools to automate our workflows:
- Build Health: We are developing agents to automatically fix build errors in our Git branches.
- Conflict Resolution: When rebasing our patches on new WebRTC releases, we encounter merge conflicts. We are training AI agents to resolve the majority of these conflicts automatically, leaving only the most complex architectural changes for human engineers.
Acknowledgements
This work was accomplished by a small team of engineers who recognized the value of this strategic project and dove in head-first despite its complexity. They brought creative ideas and solutions, did the heavy lifting, and ultimately drove the project to completion in the face of unexpected blockers and unique challenges along the way: Dor Hen, Guy Hershenbaum, Jared Siskin, Liad Rubin, Tal Benesh, and Yosef Twaik.
The post Escaping the Fork: How Meta Modernized WebRTC Across 50+ Use Cases appeared first on Engineering at Meta.
This post first appeared on Read More