The hardest concurrency bugs don’t happen inside a JVM. They happen when multiple services all think they’re right.
Most developers learn concurrency through threads, locks, synchronized blocks, and thread pools.
Those concepts matter. But a meaningful category of production outages happens after all of that is already correct. The JVM model is fine. The code is correct. The tests pass.
The real problems start when multiple servers, schedulers, consumers, caches, and services begin interacting — each making independent decisions, each working from a local view of a shared world.
These are five failures that illustrate what that looks like in practice.
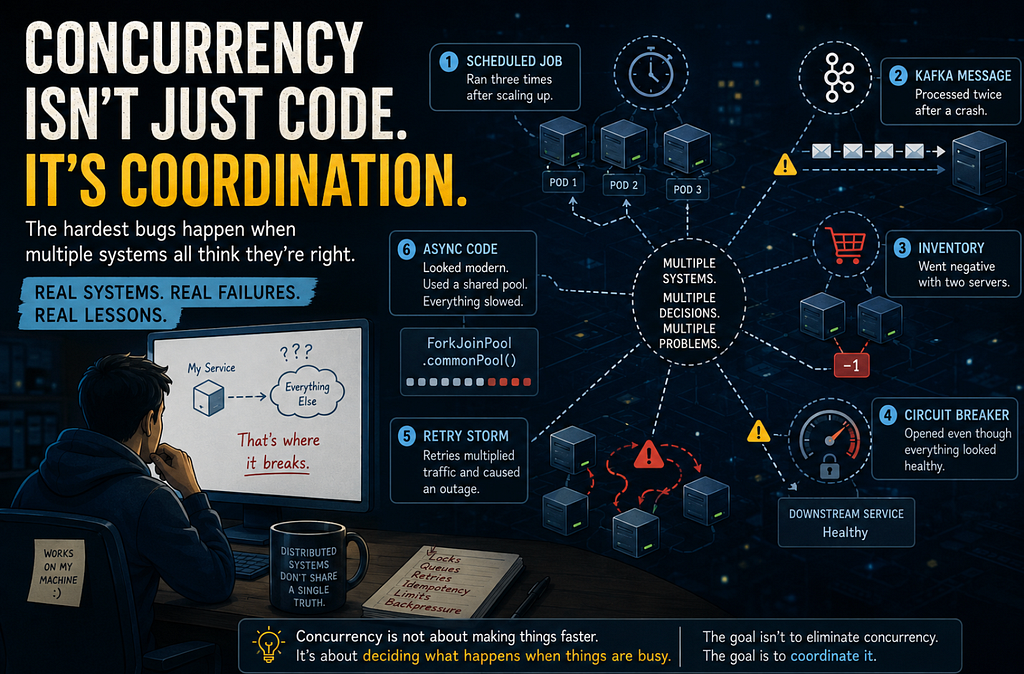
The Scheduler That Worked Fine Until It Didn’t
For over a year, a @Scheduled job ran without incident — processing end-of-day orders, sending confirmations, generating reports.
Then the service scaled to three Kubernetes replicas.
Within a day: duplicate emails, doubled reports, one customer charged twice. No code had changed. Nobody could explain it immediately, because the job was working exactly as written.
@Scheduled(fixedRate = 60000)
public void processOrders() {
// unchanged for fourteen months
}
@Scheduled runs once per minute per JVM. Three pods means three executions. The annotation makes no global promise — it never claimed to. Most engineers don’t think about this until scale-up makes it visible.
The standard fix is distributed locking. ShedLock is the common choice for Spring Boot: a shared lock store (Redis, a database table) ensures only one node runs the job while others skip. The pattern is well-understood.
What’s less obvious is calibrating expiry. Set it too short and a second node acquires the lock before the first finishes under load. Set it too long and a crashed node holds the lock until manual cleanup. The right value isn’t the average job duration — it’s the realistic worst-case duration, with room for slow infrastructure days.
Most teams discover the correct expiry after watching the naive value fail once in production.
Idempotency Isn’t A Kafka Problem
Two days of investigation. Payment service logs showed a single request per customer. Kafka showed a single message per order. The deduplication logic looked correct.
Duplicate charges were still appearing — infrequently, clustering around deployments and rolling restarts.
The issue was the gap between writing to the database and committing the offset.
Kafka’s at-least-once delivery guarantee means exactly what it says: the message will arrive, and under failure conditions — crashes, rebalances, timeouts — it may arrive again. When a consumer processes a message and then crashes before the offset commit, Kafka has no record that the work was done. The message reappears. This is correct Kafka behavior.
The problem wasn’t Kafka. It was that the payment logic was written assuming single delivery. That assumption doesn’t survive production.
The right framing for this class of problem isn’t “how do I prevent duplicates from Kafka” — it’s “how do I design processing that’s safe to run twice.” For payment operations, that means idempotency keys: a transaction ID checked before any charge is applied, persisted atomically alongside the result. If the ID already exists, return the previous result and skip the work. The second delivery becomes a no-op.
This pattern appears everywhere once you start looking for it: order creation, inventory updates, notification dispatch. Any operation triggered by a message needs to be safe under redelivery. In systems with regular deployments and pod restarts, redelivery isn’t an edge case — it happens on a schedule.
The mental shift is treating idempotency as a design constraint from the start rather than a patch applied after the first duplicate incident. These are different amounts of work.
Part of a series on system design, production engineering, and the interview questions that reveal how engineers actually think under pressure. And if you’re preparing for practical engineering interviews or trying to improve production-level thinking beyond just solving DSA problems, I’ve also been exploring platforms like PracHub.
Redis Is Atomic. Workflows Aren’t.
A flash sale. One item in stock. Two users add it to their cart simultaneously on different application servers.
Both servers query Redis: inventory is 1. Both validate. Both proceed. Inventory is decremented twice. It goes to negative one.
The immediate reaction is usually: “Redis is single-threaded. How?”
Individual Redis commands are atomic. The workflow — GET the value, evaluate it in application code, conditionally DECR — spans three round-trips with application logic running between them on two separate servers. Another server can move through the same sequence in those gaps.
Server A: GET inventory → 1
Server B: GET inventory → 1
Server A: inventory > 0, proceed
Server B: inventory > 0, proceed
Server A: DECR inventory → 0
Server B: DECR inventory → -1
Redis’s single-threaded execution doesn’t close these gaps. The race exists between commands, not inside them.
The fix is moving the entire decision into one atomic operation. A Redis Lua script runs without interruption — no client can interleave commands against those keys while the script executes.
local inventory = redis.call('GET', KEYS[1])
if tonumber(inventory) > 0 then
redis.call('DECR', KEYS[1])
return 1
end
return 0Check and decrement happen as one operation. The gap disappears.
This is the same principle behind database transactions. A read followed by a conditional write is only safe if the world can’t change between them. In a distributed system with multiple writers, assuming that gap is safe is where races live. Redis doesn’t change the principle — it just changes which layer enforces it.
A Healthy Dependency Can Still Exhaust You
The circuit breaker opened mid-afternoon. On-call pulled up every dashboard.
CPU: 30%. Memory: comfortable. Database response time: 380ms, up from the usual 80ms — elevated during a scheduled batch job, but well within what most teams would consider operational. No error rate on the database itself. No obvious cause for a full circuit breaker trip.
What took too long to find was thread pool utilization, which wasn’t on the primary dashboard.
The database hadn’t failed. It had slowed. But 380ms instead of 80ms meant each request held a connection and a thread roughly five times longer than the pool sizing assumed. With the same incoming request rate, the pool filled up. New requests waited for a free thread. Waits exceeded timeouts. Timeouts registered as failures. The circuit breaker saw a rising failure rate and opened.
The interesting part: none of the components behaved incorrectly. The database was slower but healthy. The circuit breaker opened on legitimate failure signals. The thread pool behaved exactly as a bounded pool should. The failure emerged from the interaction — a latency increase that was individually unremarkable but collectively catastrophic given how the pool was sized.
Thread pool sizing is a latency assumption encoded in infrastructure configuration. Most teams set it once, during initial deployment, based on expected response times under normal load. When latency increases — even modestly, even temporarily — that assumption breaks. The result is a circuit breaker opening for what looks like no reason, because everyone is checking the wrong layer.
The fix is bulkheads: separate pools per downstream dependency, sized independently, so a database slowdown doesn’t cascade into an application-wide failure. The more durable fix is treating thread pool sizing as a variable that needs to be revisited when latency profiles change — not as a constant.
The Lock That Was Held By A Process That Had Stopped
This one is less common than the others but worth understanding because the failure mode is genuinely surprising.
A service used a distributed Redis lock to ensure exactly one node ran a critical section at a time. The pattern worked correctly for months. Then in production, two nodes simultaneously believed they held the lock — and both executed the critical section.
The sequence:
Node A acquires lock (TTL: 30 seconds)
Node A begins critical section
JVM garbage collection pause: 35 seconds
Lock TTL expires
Node B acquires lock
Node B begins critical section
Node A GC pause ends
Node A resumes — still believes it holds the lock
Both nodes are now inside the critical section
Redis expired the lock correctly after 30 seconds of silence. Node B correctly acquired an available lock. Node A resumed from a pause with no awareness that time had passed or that the lock had been reclaimed.
A JVM can pause for GC for longer than most engineers expect, particularly under memory pressure or with older collector configurations. During a pause, the wall clock keeps moving. Redis TTLs keep expiring. Other nodes keep running. When the paused process resumes, it has no mechanism to know what changed while it was stopped.
This is a fundamental property of distributed systems: a process can be paused, rescheduled, or preempted at any point, for any duration, with no visibility into what happened in the interim. A lock with a TTL is a time-bounded promise — valid for as long as the holder is active, but expiring regardless of whether the holder is aware.
Fencing tokens reduce the risk: each lock acquisition gets a monotonically increasing token, and the resource being protected rejects operations with stale tokens. Heartbeat renewal keeps the TTL refreshed while work is ongoing. Neither eliminates the problem entirely — they reduce the window or the consequences.
The practical takeaway is that a distributed lock is a probability reducer, not a guarantee. Designing around it as though it’s infallible is how this failure mode appears in production.
What These Have In Common
Across all five: the individual components behaved correctly.
The scheduler ran on schedule. Kafka delivered messages reliably. Redis executed commands atomically. The circuit breaker opened on legitimate failures. The lock expired when it should have. Every component did exactly what it was designed to do.
The failures emerged from assumptions that didn’t survive the multi-node, multi-process reality of a production system. Assumptions about global uniqueness, about exactly-once delivery, about what “atomic” means at the workflow level, about what “healthy” means when it feeds into resource contention, about what “held” means when a process can pause mid-execution.
In Part 1 of this series, the problems were inside threads. In Part 2, they were inside queues. Here they live in the spaces between components — in the coordination layer that doesn’t have a dashboard, doesn’t throw exceptions, and often doesn’t produce obvious symptoms until something has already gone wrong.
Distributed systems don’t fail at the component level. They fail at the agreement level. And agreement is one of the harder things to get right when every participant is making decisions independently, from an incomplete view of a world that won’t stop moving.
Running into these in production? I’d enjoy hearing what the failure looked like from the inside.
Part of a series on system design, production engineering, and the interview questions that reveal how engineers actually think under pressure. And if you’re preparing for practical engineering interviews or trying to improve production-level thinking beyond just solving DSA problems, I’ve also been exploring platforms like PracHub.
![]()
Most Java Developers Can’t Answer These Concurrency Questions. Can You? (Part 3) was originally published in Javarevisited on Medium, where people are continuing the conversation by highlighting and responding to this story.
This post first appeared on Read More