One of the biggest surprises I had while building Retrieval-Augmented Generation (RAG) systems wasn’t related to Large Language Models.
It wasn’t embeddings.
It wasn’t vector databases.
It wasn’t even prompt engineering.
It was discovering how often the right document was retrieved but never became the document the model actually used.
At first, this didn’t make sense.
The retrieval pipeline was working.
Similarity search returned relevant chunks.
Yet the generated answer still felt incomplete.
Sometimes it referenced a secondary document instead of the primary one.
Other times it completely ignored the most authoritative information in the knowledge base.
For weeks I assumed the model was making poor decisions.
It wasn’t.
The retrieval layer was.
More specifically, I was missing an entire architectural component that many production AI systems quietly depend on:
Re-Ranking.
Once I introduced re-ranking into my retrieval pipeline, answer quality improved far more than I expected.
Not because the model became smarter.
Because the model finally received better context.
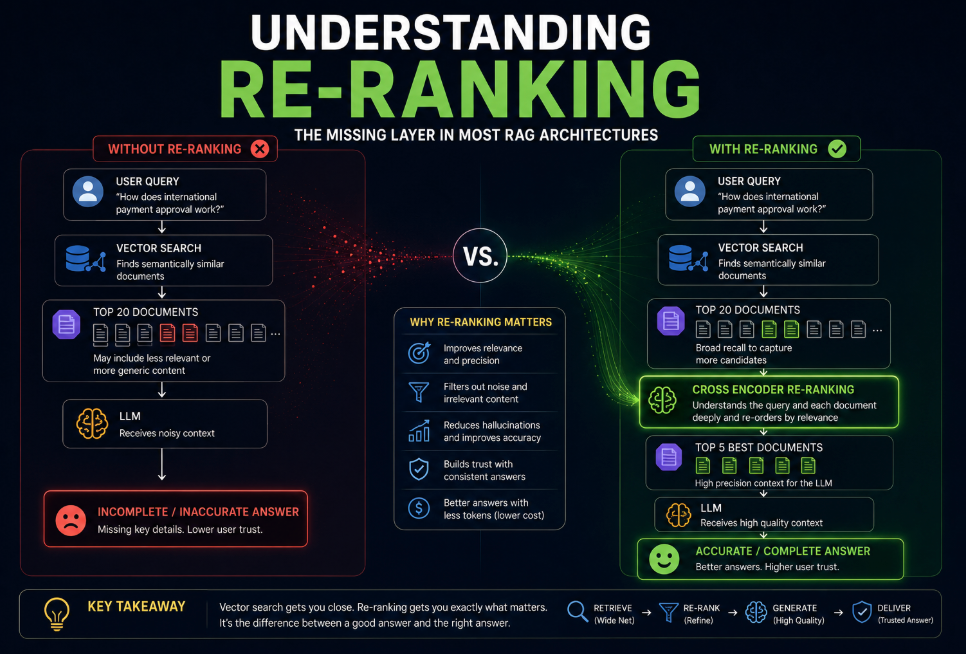
Why Retrieval Isn’t the End of the Story
Most RAG tutorials describe retrieval like this:
User Question
│
▼
Embedding
│
▼
Vector Database
│
▼
Top 5 Results
│
▼
LLM
This architecture works.
For demos.
Unfortunately, vector similarity doesn’t necessarily return the documents that are most useful.
It returns the documents that appear most semantically similar.
Those aren’t always the same thing.
A Real Example
Imagine a banking knowledge base.
A user asks:
“How does international payment approval work?”
The vector database retrieves:
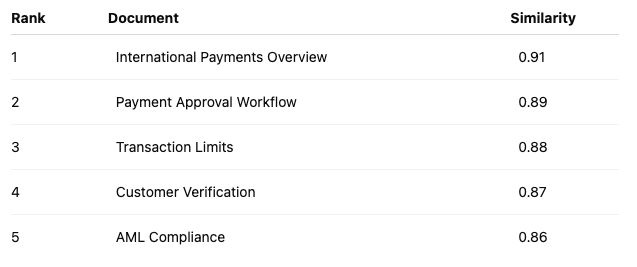
At first glance, everything looks fine.
But notice something.
The document that actually explains approval workflow isn’t ranked first.
Instead, a generic overview document is.
If the LLM primarily focuses on the first few chunks, the generated answer becomes less precise.
This isn’t a model problem.
It’s a ranking problem.
Similar Doesn’t Always Mean Relevant
This is probably the biggest misconception about vector search.
Embedding similarity measures semantic closeness.
It does not measure usefulness.
Consider these two documents.
Document A
“International payments are financial transactions involving two countries…”
Document B
“Transactions exceeding $50,000 require dual managerial approval.”
The first document is semantically closer to the query.
The second document actually answers it.
Without re-ranking, the wrong document often receives more attention.
What Re-Ranking Actually Does
Think of vector search as casting a wide fishing net.
Its objective is recall.
Find as many potentially relevant documents as possible.
Re-ranking has a different objective.
Precision.
It asks:
“Out of these retrieved documents, which ones are actually the best answers to this specific question?”
The architecture now becomes:
User Question
│
▼
Vector Search
│
▼
Top 20 Chunks
│
▼
Re-Ranking Model
│
▼
Best 5 Chunks
│
▼
LLM
That extra layer often has a dramatic impact on response quality.
Why Vector Search Gets Confused
Imagine searching for:
“Spring Boot authentication.”
Your vector database may retrieve:
- Spring Boot Overview
- Spring Security Introduction
- OAuth Guide
- JWT Authentication
- Authentication Filters
Every document is related.
But not equally useful.
Vector search lacks deep contextual understanding of intent.
Its job is to retrieve.
Not judge.
Re-ranking performs that second step.
Think Like a Search Engine
Google doesn’t simply return every webpage containing your keywords.
It performs multiple ranking stages.
Thousands of signals determine what appears first.
Modern RAG systems follow the same philosophy.
Vector retrieval finds candidates.
Re-ranking decides the winners.
Cross Encoders: The Secret Behind Re-Ranking
Most embedding models work independently.
The query becomes one vector.
The document becomes another vector.
Similarity is calculated mathematically.
Cross Encoders work differently.
Instead of comparing vectors independently, they process:
Question
+
Document
together.
This allows the model to evaluate:
- intent
- context
- relationships
- sentence meaning
rather than relying solely on vector distance.
The trade-off?
Cross Encoders are slower.
But they’re dramatically better at ranking.
Retrieval vs Re-Ranking
I like to explain it this way.
Retrieval asks:
“Which documents might be useful?”
Re-ranking asks:
“Which documents are actually the best?”
One optimizes recall.
The other optimizes precision.
Production systems need both.
Why Re-Ranking Reduces Hallucinations
Earlier I believed hallucinations happened because models generated incorrect information.
Now I think many hallucinations begin much earlier.
Consider this pipeline.
Question
↓
Vector Search
↓
20 Relevant Chunks
↓
Wrong Ranking
↓
LLM
↓
Incorrect Answer
Notice something.
The correct answer already existed.
The model simply received less useful context.
Re-ranking doesn’t increase model intelligence.
It improves information quality.
The Cost of Skipping Re-Ranking
Without re-ranking:
- More irrelevant context
- Larger prompts
- Higher token costs
- Lower precision
- More hallucinations
- Lower user trust
Ironically, many teams compensate by retrieving more documents.
This usually makes things worse.
More documents increase noise.
The better solution is:
Retrieve more.
Send less.
How I Would Design a Production Retrieval Pipeline
If I were designing a modern enterprise RAG platform today, my retrieval layer would look something like this.
User Query
│
▼
Embedding Model
│
▼
Hybrid Search
(Vector + BM25)
│
▼
Top 50 Candidates
│
▼
Metadata Filtering
│
▼
Cross Encoder Re-Ranking
│
▼
Top 5 Documents
│
▼
Prompt Builder
│
▼
LLM
Every stage removes noise.
Every stage improves signal quality.
By the time the model generates a response, it has already been given the best possible evidence.
When Re-Ranking May Not Be Necessary
Like every engineering decision, re-ranking involves trade-offs.
Small document collections may not benefit much.
Simple FAQ bots often perform well with semantic search alone.
But as your knowledge base grows:
- thousands of documents
- multiple departments
- overlapping terminology
- similar documents
re-ranking becomes increasingly valuable.
The larger the corpus, the more important ranking quality becomes.
The Biggest Lesson I Learned
One of the most valuable lessons from building RAG systems is this:
The model isn’t always the bottleneck.
Sometimes the problem isn’t generation.
Sometimes it’s retrieval.
Sometimes it isn’t even retrieval.
It’s the order in which retrieved information reaches the model.
That subtle distinction completely changed how I evaluate AI systems.
Today, when someone tells me their chatbot produces inconsistent answers, I don’t immediately ask:
Which model are you using?
I ask:
How are you retrieving your documents?
And almost immediately afterward:
Are you re-ranking them?
Those two questions usually reveal more about answer quality than the model itself.
Final Thoughts
The AI community spends enormous energy discussing larger models, longer context windows, and better prompts.
Those topics deserve attention.
But after building multiple RAG systems, I’ve become convinced that one of the most underrated improvements you can make isn’t replacing the model.
It’s improving what the model reads.
Retrieval gets the model close.
Re-ranking gets it right.
And in production AI systems, that small architectural layer often makes the difference between a chatbot that merely sounds intelligent and one that consistently delivers trustworthy answers.
![]()
Understanding Re-Ranking: The Missing Layer in Most RAG Architectures was originally published in Javarevisited on Medium, where people are continuing the conversation by highlighting and responding to this story.
This post first appeared on Read More