
Implementing local-first agentic AI: A practical guide
In our previous article, “Small Language Models: Why the future of AI agents might be tiny,” we described the idea of Small Language Models (SLMs), specialized language models with a small footprint to be executed on the edge of the internet (e.g., your laptop, tiny server farms, etc). In the follow-up article, “How to build agentic AI when your data can’t leave the network,” we established the architectural need for specialized SLMs when building privacy-first agentic systems. We argued that for organizations (or use cases) with strict data locality and confidentiality constraints, the model should run locally by default, escalating to the cloud only for non-critical tasks, such as stylistic text rewriting. This architecture, informed by research like ThinkSLM: Towards Reasoning in Small Language Models (EMNLP 2025), separates concerns: reasoning, retrieval, and expression are handled by specialized, auditable, and cost-effective local models.

However, theory has to meet practice. An architecture is only as useful as its implementation. This follow-up shifts the focus from the why to the how, walking through the concrete steps needed to bring the “Local First, Cloud Last” design to life. We cover environment setup, a practical enterprise use case, and a simple testing approach to show that privacy-first agents are not just a theoretical ideal, but a deployable pattern. In that sense, this article serves as the final piece in the SLM trilogy.
Enterprise use case: HR triage system
Smaller Language Models (SLMs) can run easily with a lighter on-premises setup, sometimes even on a standard laptop without a dedicated GPU, as demonstrated by the example discussed here.
SLMs are particularly effective in scenarios where a cloud-based architecture is not feasible, such as when strict privacy compliance is required. To illustrate this, we developed a simple Human Resources (HR) triage system. This system is designed to handle sensitive employee reports and uses a multi-model pipeline to classify the reports, generate a remediation plan, and execute necessary actions.
The system processes a brief incoming HR report, identifying the nature of the problem described (e.g., harassment, burnout, performance, etc.). For instance, the code in the repository uses the following sample text:
My Employee ID is 12345: I have been working excessive hours for months.
My manager threatens retaliation if I raise concerns,
and I am feeling mentally exhausted and unsafe.
The first model understands that this report describes a case of burnout. The next model is the planner, which decides which steps are in the plan to address this report. A possible output is:
[
{
"stepdescription": "Create a formal HR case documenting the employee's excessive working hours, perceived threats of retaliation, and resulting mental exhaustion",
"employeeid": "12345",
"category": "burnout",
"severity": "HIGH"
},
{
"actiontype": "Arranging a confidential meeting with HR",
"employeeid": "12345",
"priority_level": "MEDIUM"
}
]
The plan’s steps are described at a high level. The final model is responsible for mapping this general description to a specific, executable function. It selects the most appropriate function based on the step’s description and then executes it. While the implementation in our current code is a simple Python function that prints arguments, this step can be generalized to an API call, a handoff to another specialized model, or a similar action in a real-world scenario. Following the execution of the “real” functions:
[STEP]
{'stepdescription': "Create a formal HR case documenting the employee's excessive working hours, perceived threats of retaliation, and resulting mental exhaustion", 'employeeid': '12345', 'category': 'burnout', 'severity': 'HIGH'}
[EXECUTE] openhrcase with arguments {'category': 'burnout', 'employeeid': '12345', 'risklevel': 'HIGH'}
[ACTION] Open HR case for employee=12345, category=burnout, risk=HIGH
[STEP]
{'actiontype': 'Arranging a confidential meeting with HR', 'employeeid': '12345', 'prioritylevel': 'MEDIUM'}
[EXECUTE] schedulehrmeeting with arguments {'employeeid': '12345', 'urgency': 'MEDIUM'}
[ACTION] Schedule HR meeting for employee=12345, urgency=MEDIUM
In the [STEP] log, the step to be executed is described. The [EXECUTE] section maps that step to the specific function being called, along with the arguments extracted from the description. Finally, [ACTION] reports the result of the function execution.
Project setup
The working project is available on GitHub. Given that the architecture employs 1–3B models, standard, readily available hardware is typically adequate. The system demonstrated surprisingly good performance even in tests on a laptop without a dedicated GPU, with the entire pipeline generally executing within 10–30 seconds. A note worth noting: typically, when talking about architecture, measuring the number of tokens per second is always reported, but here, it is not a priority; we want this to be runnable almost everywhere and, most importantly, locally. Of course, everything here can gracefully be run on a GPU.
Implementation breakdown
The system leverages intent detection to categorize reports (for example, harassment or burnout), a planner to create step-by-step action plans, and a tool executor to perform actions such as opening HR cases or scheduling meetings.
| Pipeline Stage | Model Name | Typical Size | Note |
|---|---|---|---|
| Intent detection | sentence-transformers/ all-MiniLM-L6-v2 |
~90M | Classifies employee reports into predefined HR categories (for example, harassment, burnout, or policy violation). Employs the all-minilm model to generate embeddings for both the input text and predefined intent categories.
Calculates cosine similarity to determine the closest matching intent. |
| Planner / Reasoning | microsoft/ Phi-3-mini-4k-instruct |
~3.8B | Generates an ordered plan of actions to address the detected intent.Leverages the phi3:mini model to create structured JSON plans based on the employee report and detected intent.
Includes error handling for non-JSON outputs. |
| Tool / Action execution | google/ function-gemma-2b-it |
~2B | Executes the planned actions using predefined HR tools. Relies on the functiongemma model for constrained function calling. |
| Agent manager (Orchestrator) | Classic code (Python) | n/a | Coordinates the entire pipeline (intent detection, planning, execution). Handles the flow of data through the pipeline and ensures each step is executed in sequence. |
The following image shows the complete architecture. Components that were part of the general solution in the previous article are greyed out here:
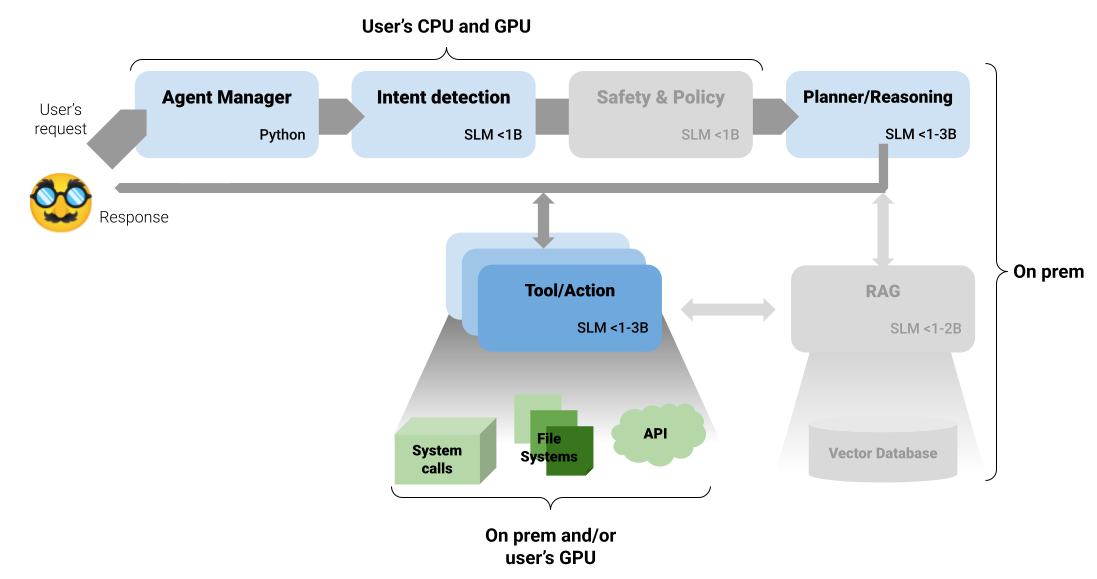
Note: For simplicity, the current implementation does not include Safety and Policy filtering, as the intended model (deberta-v3-small) is not available in a format compatible with Ollama. Another greyed-out component is the RAG. We have no additional source of information (e.g., documents, databases, etc.), so we don’t need to set up a RAG component here. You can compare this image with the more general version from the previous article.
Here is a short description of all the source files you will find in the repo:
- main.py – The system’s entry point. It runs the full workflow end-to-end using a sample employee report
- agent.py – The orchestrator. It coordinates intent detection, planning, and execution
- intent_detector.py – Identifies the intent of the input string using MiniLM embeddings, then maps it to one of the predefined intents
- planner.py – Produces an ordered action plan based on the detected intent using the Phi-3 Mini model
- executor.py – Carries out the plan steps using constrained function calls via the Function Gemma framework
- hr_tools.py – Where the use case lives. In this example, it contains HR-specific helpers for employee reports, like opening and scheduling meetings. If you’re adapting the repo to a different domain, this is usually the first file you’ll customize
- utils.py – A grab bag of utilities, like cleaning up JSON responses. Since models can be inconsistent about formatting, we use a cleanup step instead of relying on prompts to avoid the usual
jsonwrapping
Conclusion
The Local First, Cloud Last architecture represents a practical shift in how AI systems can be designed for privacy-sensitive environments. Moving beyond theory, it shows that this approach is both robust and achievable today using existing open-source models and modest local compute resources.
By assigning Small Language Models to well-defined roles – such as classification, reasoning, and constrained retrieval- we achieve privacy by design while improving reliability, auditability, and cost efficiency. This stands in contrast to architectures centered around a single, large, remotely hosted LLM, which often introduce unnecessary cost, latency, and compliance risk for many enterprise workloads. Conversely, SLMs demand more careful prompt engineering. Unlike the flexibility offered by LLM, SLMs are highly sensitive to minor changes in task description, requiring precise input. However, this trade-off is balanced by the significant advantage of easy, local testing, which eliminates the cost and time associated with paid tokens.
There is a growing perception that the current AI ecosystem, increasingly dominated by ever-larger LLMs, may be inflating a bubble that will eventually reshape how language models are used. To an extent, this concern is justified. Large models are undeniably powerful, but they also require significant infrastructure, energy, and continuous oversight to operate safely. Small language models offer a different trade-off: they have a much smaller operational footprint, can run at the edge, on-premise, or even on mobile devices, and can be tightly specialized for specific tasks. Rather than a fallback, SLMs represent a stable and sustainable foundation for many real-world systems, particularly in environments where control, privacy, and predictability matter more than maximal expressivity.
The post Implementing local-first agentic AI: A practical guide appeared first on LogRocket Blog.
This post first appeared on Read More