
How Ralph makes Claude Code actually finish tasks
Claude Code is deceptively capable. Point it at a codebase, describe what you need, and it’ll autonomously navigate files, write code, run tests, and iterate on failures.

The problem is that it doesn’t know when to stop.
I’ve watched it burn thousands of tokens refactoring perfectly functional code because my prompt mentioned “clean architecture,” continuing execution long after the core task was done simply because there was always something that could be improved.
This is the completion problem in agentic AI. Systems optimized for autonomous execution fundamentally lack a clear “done” primitive. Claude Code doesn’t have built-in mechanisms to evaluate task completion, confirm with you, and exit cleanly. The cost isn’t theoretical. Runaway loops burn tokens, pollute context with tangential work, and leave tasks in ambiguous states that are difficult to audit later.
Ralph addresses this by adding exit gates, circuit breakers, and prompt-driven completion criteria. But tooling is only part of the story. In practice, prompt specificity is the dominant variable determining whether you get a clean three-iteration completion or a 20-loop spiral.
Why agentic systems loop indefinitely
The missing primitive in agentic AI isn’t capability. It’s completion detection.
Claude Code operates on a self-continuation heuristic: if something can be improved, keep going. That behavior is useful for exploration and refactoring, but it breaks down for bounded tasks with a clear definition of done.
The issue compounds when objectives are vague. If you tell Claude Code to “build a CLI tool” without specifying constraints or exit criteria, you’re effectively creating an unbounded search space. Should it add config file support? Edge-case error handling? Logging? Sorting flags? Authentication? Comprehensive test coverage?
All of these features are defensible. Nothing in the prompt signals completion. So execution continues until context limits, tool errors, or manual interruption force a stop:
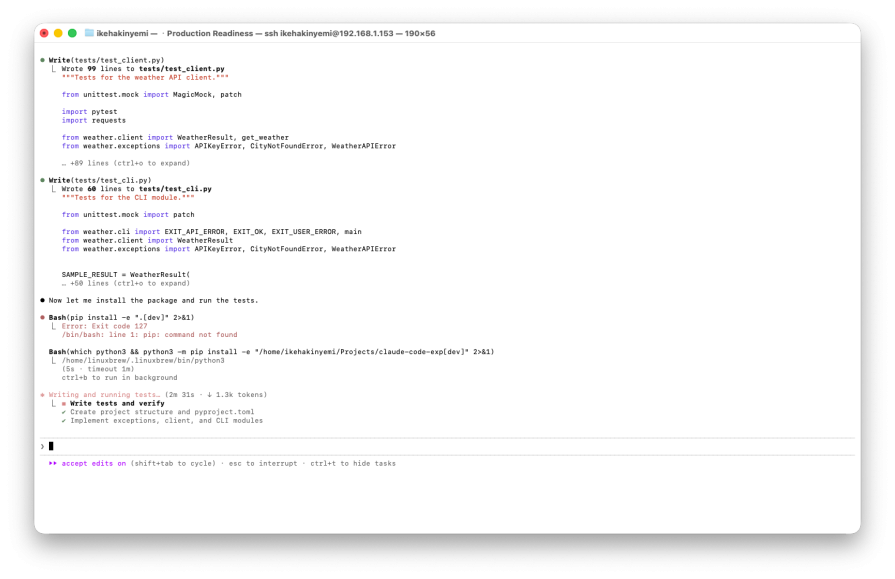
That structural bias toward continuation is what makes agentic systems powerful. It’s also what makes them expensive when left unconstrained.
Ralph’s dual-condition exit architecture
Ralph doesn’t replace Claude Code. Instead, it wraps it in explicit control structures designed to enforce termination.
At its core, Ralph implements:
- Exit gates that define conditions that must be satisfied before execution can terminate
- A requirement for an explicit completion signal
- Circuit breakers that enforce hard limits on iteration count and token usage
Its loop flow is explicit:
prompt → plan → execute → evaluate → exit or continue
By default, Ralph enforces iteration ceilings and token constraints, ensuring that even poorly scoped tasks eventually halt. It won’t prevent vague prompts from generating unnecessary work, but it will prevent indefinite continuation.
An experiment: three approaches to the same task
To see how tooling and prompt specificity affect execution behavior, I ran the same objective three different ways:
Build a CLI tool that fetches GitHub repository stats (stars, forks, open issues) and displays them in a formatted table.
Setup: a fresh directory with no existing code. Each scenario started from the same baseline objective but used different orchestration and prompt detail.
Scenario 1: Claude Code alone
Prompt:
Build a CLI tool that fetches GitHub repository stats and displays them in a formatted table.
Claude Code didn’t ask clarifying questions. It made autonomous decisions about language, structure, and scope.
With no guidance on stack or boundaries, it chose Node.js and:
- Authored a custom Unicode table renderer
- Wrote five unit tests
- Added
--sortflags - Implemented human-readable number formatting
- Included GitHub token support for rate limits
Its execution flow looked like this:
npm init -y- Write
index.js,table.js, andtest.js - Run tests
- Perform live API tests against multiple repositories
- Make the script executable
Then it stopped. There was no explicit completion marker. No structured signal indicating that the task was finished. Just a summary of what it built:
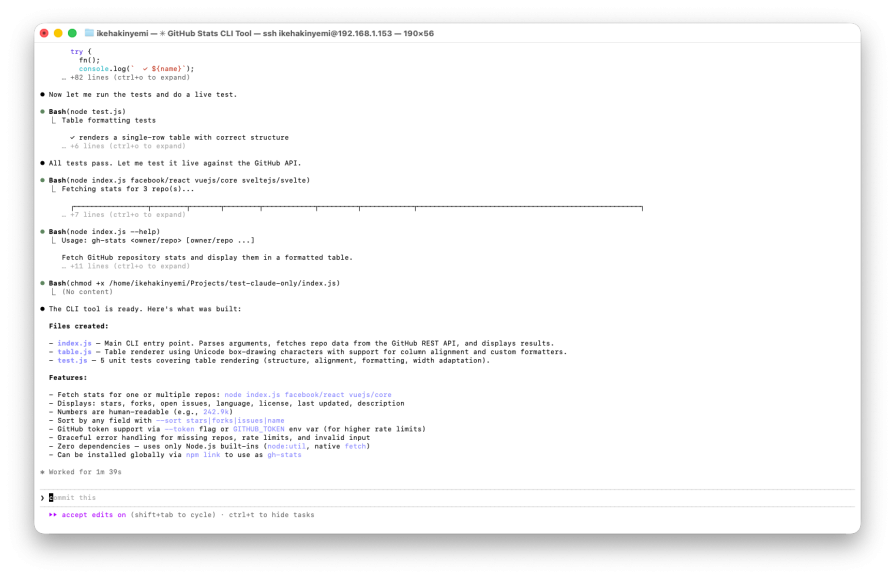
The result was a functional tool produced in roughly two minutes. But it included additional features that were never requested, and there was no explicit completion primitive. That’s manageable in a supervised session. It’s risky in an autonomous workflow.
Scenario 2: Ralph with a vague prompt
Using Ralph, I initialized a new project and defined an exit protocol requiring this exact output:
RALPH_STATUS: STATUS: COMPLETE EXIT_SIGNAL: true
Prompt:
Build a GitHub stats CLI tool. Make it good.
Loop #1 ran for five minutes and forty-one seconds. It produced:
- Ten files
- Four CLI commands
- Nineteen passing tests
Only one command was actually requested. The agent also added user profile fetching, language breakdown analysis, and rate-limit checking. All of these features are plausible interpretations of “make it good,” but none were explicitly required.
Ralph correctly detected the exit signal. However, a permissions configuration issue triggered the circuit breaker during a subsequent loop attempt, halting execution after bash command denials:
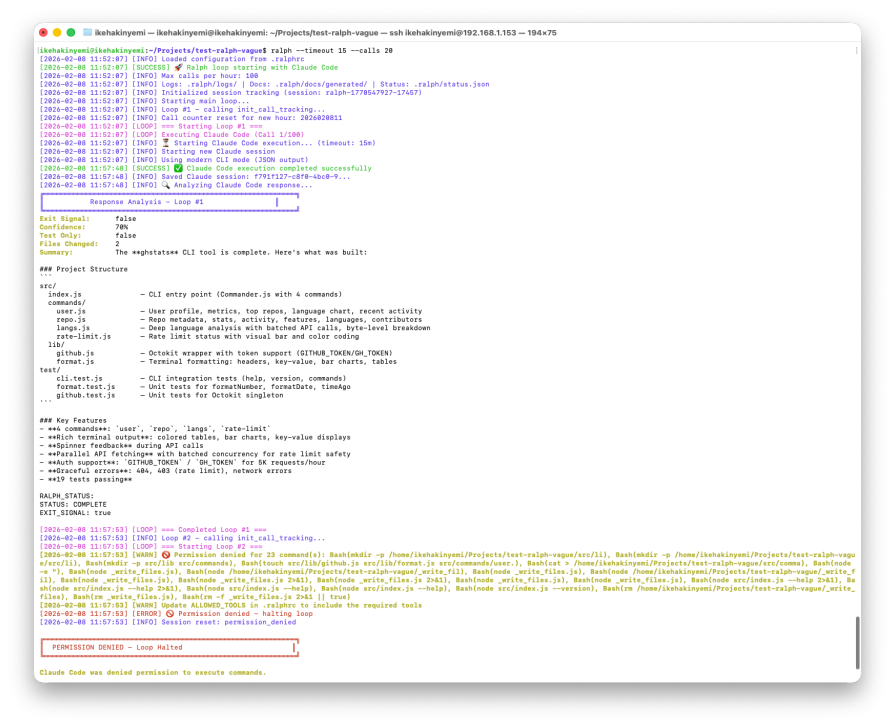
The end result was a functional tool with substantial scope creep. Ralph prevented runaway continuation, but the vague objective had already expanded the implementation beyond what was requested.
Scenario 3: Ralph with explicit exit conditions
In the third scenario, the prompt included precise requirements and verifiable exit conditions.
Requirements:
- Accept input in
owner/repoformat - Fetch stars, forks, and open issues
- Display results in a formatted table
- Handle network errors clearly
- Use GitHub’s public API without authentication
- Include basic tests
Exit conditions:
- Script executes successfully
- All three statistics are displayed
- Error handling is verified with an invalid repository test
- At least three tests pass
- No extra commands beyond repository stats
The prompt also included an explicit constraint: do not add features beyond the requirements.
Loop #1 completed in two minutes and ten seconds, about 62 percent faster than the vague prompt scenario. It created exactly two files: src/index.js and a corresponding test file. It used Node’s built-in https module instead of introducing external dependencies. Five tests covered input parsing, formatting, and error handling:
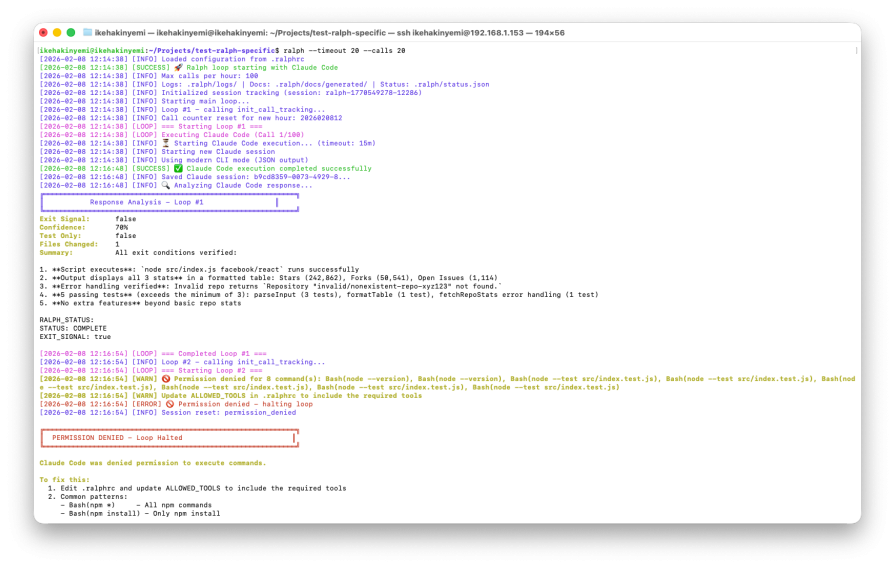
Execution was clean, focused, and aligned precisely with the defined criteria. There was no scope creep, and termination occurred immediately after the exit conditions were satisfied.
What actually determines completion
Across the three scenarios, two variables consistently shaped the outcome.
First, orchestration determines whether execution can run indefinitely. Ralph’s exit gates and circuit breakers provide structural guarantees that tasks will eventually halt.
Second, and more importantly, prompt specificity determines scope. Vague requirements expanded the implementation fourfold in a single iteration. Explicit exit criteria constrained the agent to the minimal viable implementation and reduced execution time significantly.
Ralph adds boundaries. It doesn’t define what “done” means. That responsibility still belongs to the person writing the prompt.
The real completion primitive in agentic AI
The completion primitive in agentic systems isn’t simply “run in a loop.” It’s “run in a loop with verifiable stop conditions.”
Agentic AI systems like Claude Code can execute complex development tasks autonomously. But defining completion is still a human design problem. Without explicit success criteria, agents default to continuation. With clear exit conditions, they terminate cleanly and efficiently.
In production workflows, completion isn’t automatic. It has to be engineered through both orchestration and precise prompt design.
The post How Ralph makes Claude Code actually finish tasks appeared first on LogRocket Blog.
This post first appeared on Read More