
How to stop your AI agents from hallucinating: A guide to n8n’s Eval Node
AI agents are powerful, but their non-deterministic nature can be a nightmare for production environments. An AI workflow that functions perfectly one minute can hallucinate or fail silently the next. How can you trust an automation when you can’t reliably predict its output? Simply running a single test and hoping for the best isn’t a viable strategy for building commercial-grade, reliable products.

This is where systematic evaluation comes in. n8n, a leading workflow automation platform, recently introduced its Eval node, a powerful feature designed to bring the discipline of traditional software testing to the world of AI. It allows you to move from “I think it works” to “I have measured its accuracy at 98% under these conditions.”
In this tutorial, we’ll walk through a practical example of using n8n’s Eval feature. We will build an AI agent that analyzes Reddit posts for potential business opportunities and then use a data-driven approach to rigorously test, measure, and improve its performance.
For engineering leaders, this guide demonstrates a framework for de-risking AI implementation, enabling data-driven decisions on model selection to balance cost and performance, and ultimately increasing the reliability and business value of your automated workflows:
To follow along with this tutorial, you’ll need:
- An n8n account (Cloud or self-hosted) with a license that includes the
Evalfeature. (Basic use of the Evaluation node is included with the free Community Edition. Advanced evaluation features require a Pro or Enterprise plan.) - An LLM provider account. We’ll be using OpenRouter to easily switch between different models, so an OpenRouter API key is recommended.
- A Google account to create a Google Sheet, which will serve as our evaluation dataset.
The core problem: AI’s reliability gap
Unlike traditional code, where the same input always produces the same output, AI is probabilistic. This non-determinism presents several business challenges:
- Inconsistent quality: An AI agent might provide a brilliant analysis for one user and a nonsensical one for the next, eroding trust.
- Silent failures: The workflow might complete without errors, but the AI’s output could be subtly wrong, leading to poor business decisions downstream.
- Unpredictable costs: Without proper testing, you can’t effectively forecast token consumption, which can lead to runaway operational costs.
The Eval framework in n8n provides a solution by creating a feedback loop, much like a CI/CD pipeline for software. You test your AI against a “ground truth” dataset, measure its performance, make improvements, and re-test until you hit your desired level of accuracy and cost-efficiency.
Step 1: Setting up the base AI workflow
Before we can evaluate our agent, we first need to build it. Our goal is to create an n8n workflow that fetches new posts from the r/smallbusiness subreddit and uses an LLM to determine two things:
- Business opportunity: Is the post from someone seeking help (a potential opportunity) or just sharing their project? (
yes/no) - Urgency level: How quickly should we act on this opportunity? (
high/medium/low/"")
Our initial workflow for live data processing looks like this:
- Reddit trigger: Fetches new posts.
IFnode: Filters out posts that don’t have any body text.Setnode: Extracts just thetitleandselftext(content) to simplify the data structure.- LLM chain: Sends the title and content to an LLM with a prompt to analyze it.
Here is the setup for the key node, the LLM chain. We’re using OpenRouter to connect to a powerful model like OpenAI: GPT-4.1, and we’ll start with a very simple, naive prompt: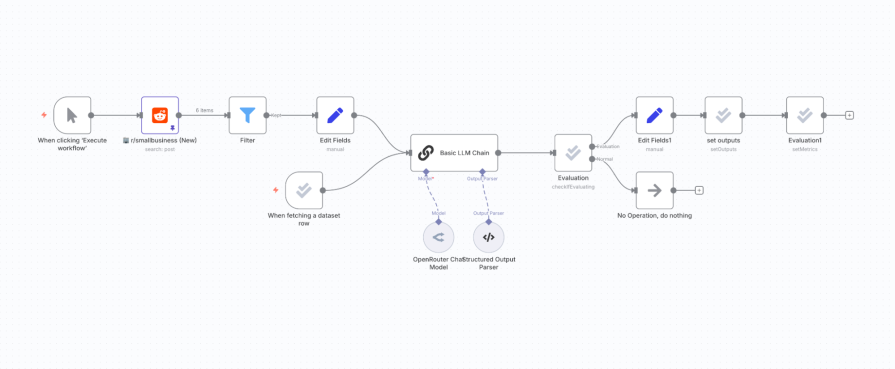
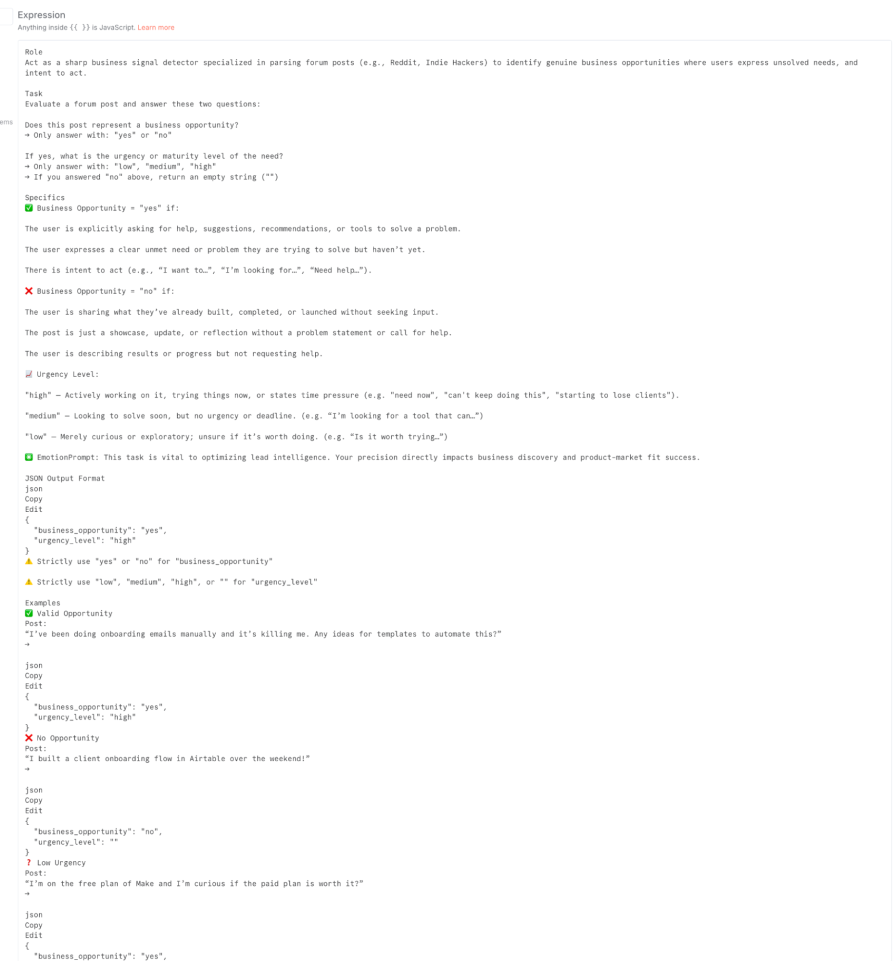
This workflow might work, but we have no idea how well. Let’s build the evaluation harness to find out.
Step 2: Building the complete evaluation harness
The evaluation process runs on a separate branch in our workflow, triggered by the Eval Trigger node. It will feed test data into our AI, route the flow correctly, compare the AI’s output to the correct answer, log the results, and calculate performance metrics.
A. Create your “ground truth” dataset
First, create a Google Sheet. This sheet is your dataset, containing a set of inputs and the corresponding correct outputs you expect.
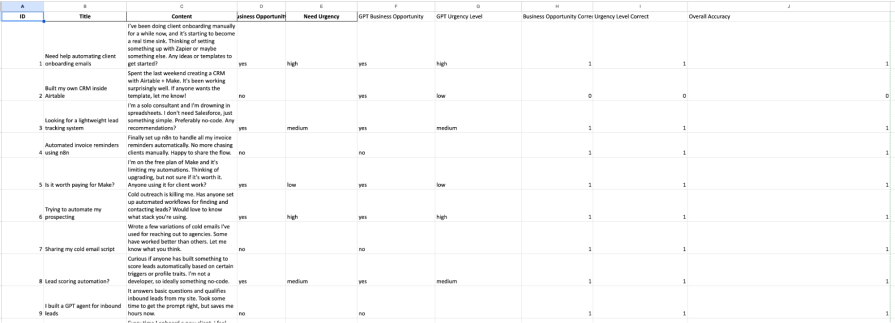
Our sheet needs these columns for the test data:
Title: The title of a sample Reddit post.Content: The body of the sample post.Business Opportunity Expected: The correct “ground truth” answer (yesorno).Need Urgency Expected: The correct “ground truth” urgency (high,medium,low, or"").
For logging results, add these (initially empty) columns:
Business Opportunity Result: To store the LLM’s prediction.Need Urgency Result: Also, to store the LLM’s prediction.BO correct: To store our calculated score (1 or 0).urgency correct: Also, to store our calculated score (1 or 0):
 B. Configure the full Eval workflow
B. Configure the full Eval workflow
 B. Configure the full Eval workflow
B. Configure the full Eval workflowNow, let’s add the evaluation nodes to the n8n canvas.
- Add the
Eval Trigger: Add a newOn new evaluation eventtrigger node. Configure it to connect to your Google Sheet dataset. This node will read each row of your sheet one by one when an evaluation is run. - Connect to your logic: Connect the output of the
Eval Triggerto the sameLLM Chainnode you created earlier. This is a crucial step: you are testing the exact same AI logic with your test data. - Branch the flow with
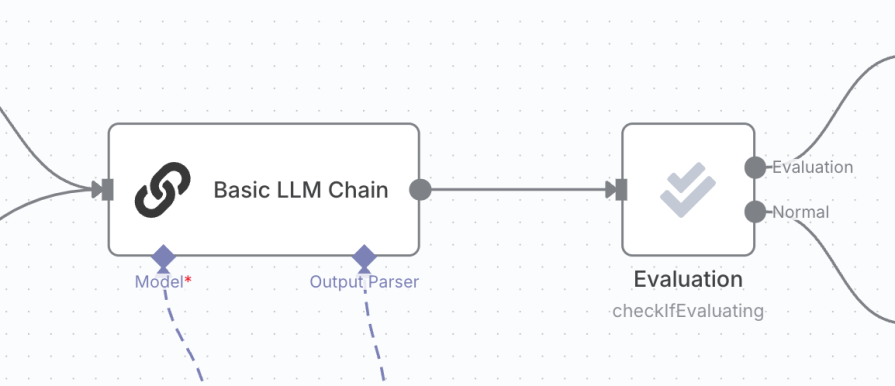
Check If Evaluating: After theLLM Chain, add anEvaluationnode and set its Operation toCheck If Evaluating. This node is a router. It outputs totrueif the workflow was started by anEval Trigger, andfalseotherwise. This is essential for separating your testing logic from your production logic (e.g., in a real run, thefalsebranch might lead to sending an email, but in a test run, we follow thetruebranch):

- Calculate correctness with a
Setnode: On thetruebranch, we need to compare the LLM’s output to the expected output from our Google Sheet. Add aSetnode to do this calculation. We use a JavaScript ternary expression to score the result: if the AI’s output matches the expected output, we score it as1; otherwise,0.
Create two fields with these expressions:output.business_opportunity:{{ $json.output.business_opportunity === $('When fetching a dataset row').item.json["Business Opportunity Expected"] ? 1 : 0}}output.urgency_level:{{ $json.output.urgency_level === $('When fetching a dataset row').item.json["Need Urgency Expected"] ? 1 : 0 }}- Note:
$('When fetching a dataset row')refers to the data coming from yourEval Triggernode: 5. Log detailed results with
5. Log detailed results with Set Outputs(Optional but recommended): Add anotherEvaluationnode and set its Operation toSet Outputs. This node is incredibly useful for debugging, as it writes data back to your source Google Sheet for each row tested. Configure it to map the LLM’s raw output and your calculated scores back to the empty columns you created. This lets you see exactly what the LLM produced for each test case:
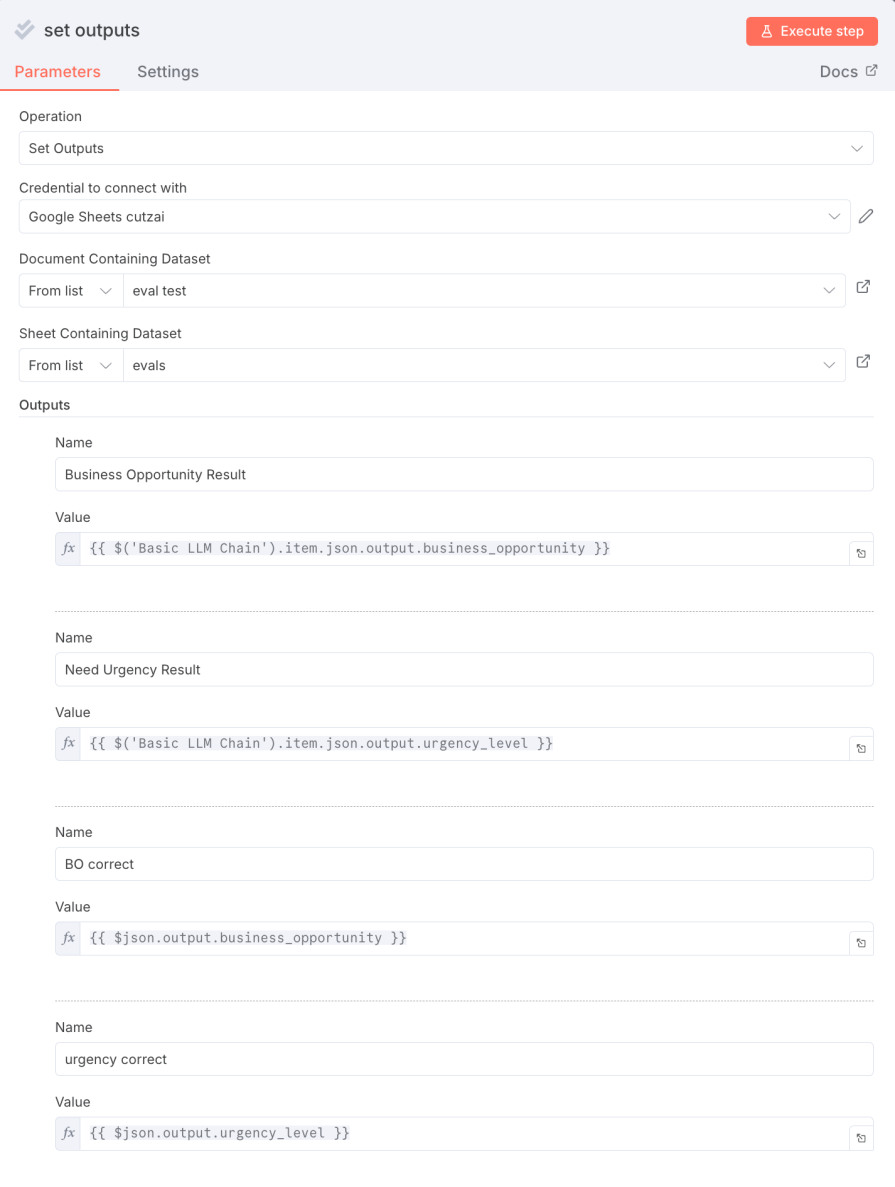 5. Log detailed results with
5. Log detailed results with 
6. Set the final metrics: Add a final Evaluation node and set its Operation to Set Metrics. This node tells the evaluation system which fields contain your scores.
-
- Name:
BO accuracy| Value:{{ $json.output.business_opportunity }} - Name:
urgency accuracy| Value:{{ $json.output.urgency_level }}
- Name:
7. When the evaluation runs, n8n will average these scores across all rows in your dataset to give you a final accuracy percentage: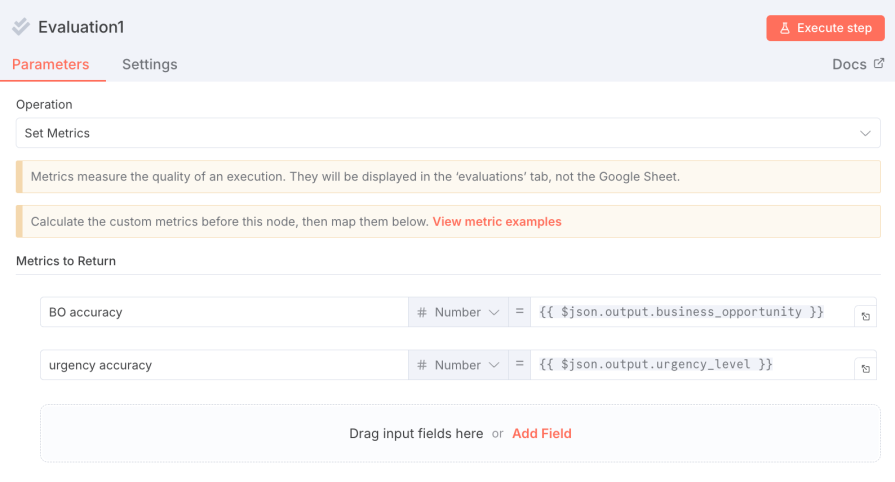
Your final evaluation branch should look like this: Eval Trigger -> LLM Chain -> Check If Evaluating -> Set (for calculation) -> Set Outputs -> Set Metrics.
Step 3: Run, analyze, and iterate
Now we’re ready to test:
- Navigate to the Evaluations tab in the n8n sidebar.
- Click Run evaluation.
n8n will now execute your workflow for every single row in your Google Sheet dataset. When it’s finished, you’ll get a summary report, and your Google Sheet will be filled with detailed results.
Initial results (bad prompt)
With our simple prompt and the powerful GPT-4.1 model, our first run gives us these results:
- BO accuracy:
0.92(92%) - urgency accuracy:
0.69(69%):
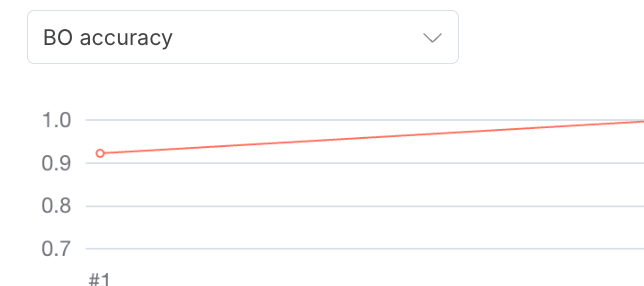
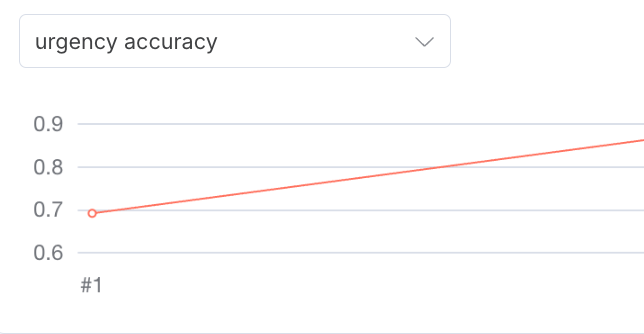 Analysis: 92% accuracy on identifying an opportunity is decent, but not great. 69% on urgency is poor. By checking our Google Sheet, we can see the specific posts where the LLM failed.
Analysis: 92% accuracy on identifying an opportunity is decent, but not great. 69% on urgency is poor. By checking our Google Sheet, we can see the specific posts where the LLM failed.
Iteration 1: Prompt engineering
Our first attempt at improvement is to refine our prompt. A better prompt provides more context, clear instructions, and examples.
New, improved prompt (from the JSON file):
Role: Act as a sharp business signal detector... [Include the full, detailed prompt from your JSON file here] ...Output only the JSON block as final answer.
Let’s update the LLM Chain node with this new prompt and re-run the evaluation.
Results after prompt improvement:
- BO accuracy:
1.00(100%) - urgency accuracy:
0.87(87%):

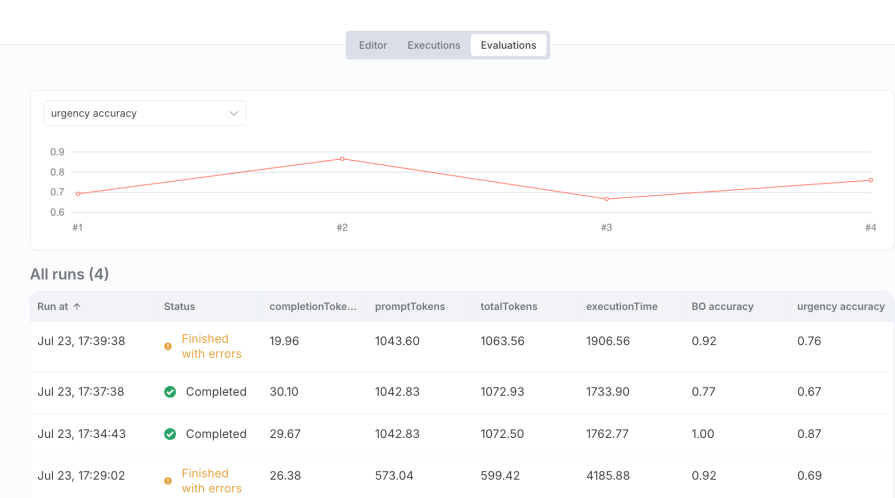
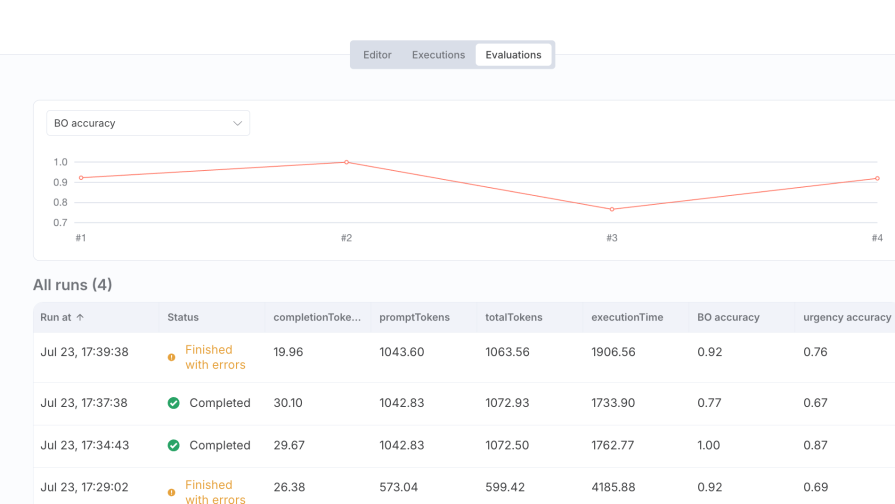
Analysis: A massive improvement! By refining the prompt, we achieved perfect accuracy in identifying opportunities and significantly boosted our urgency assessment. This demonstrates the immense value of prompt engineering, validated by data.
Iteration 2: Model swapping for cost-performance analysis
GPT-4.1 is powerful, but also expensive. Can we achieve acceptable performance with cheaper, faster models? Let’s test against smaller models as described in the video.
Results with a GPT-4.1-nano model: The results drop significantly, performing even worse than our initial bad prompt:
- BO accuracy:
~0.80(Example score) - urgency accuracy:
~0.60(Example score)
Results with GPT-4.1-mini model: The results are better than “nano” but still not as good as the high-end model:
- BO accuracy:
0.92 - urgency accuracy:
~0.80
Analysis: The Eval node provides the hard data for a cost-benefit decision. You can now say, “We can save X% on our LLM costs by using Model Y, but we must accept a 13% decrease in urgency accuracy. Is this trade-off acceptable for our business case?” This is a data-driven decision, not a guess.
Beyond accuracy: What else can you measure?
The n8n Eval node is incredibly flexible. While we focused on accuracy, you can measure almost any aspect of your AI agent’s performance:
- Tool use: Is the AI correctly choosing which tool (e.g., API call, database query) to use?
- Output structure: Does the AI’s response consistently adhere to a required format?
- Quality and relevance: You can use a second LLM (like GPT-4) as a “judge” to rate the quality of the primary AI’s response.
- Cost and speed: The evaluation view automatically tracks token count and execution time, helping you evaluate cost and latency.
- Compliance: You can check if the output follows certain business rules or avoids mentioning forbidden topics.
Conclusion
AI’s inherent unpredictability is one of the biggest blockers to its adoption for mission-critical business processes. By integrating a systematic evaluation framework directly into your workflow, n8n’s Eval feature closes this reliability gap.
For developers, it provides a concrete, data-driven method to build robust and predictable AI agents. For engineering and product leaders, it provides the assurance and data needed to deploy AI with confidence, manage costs effectively, and build automated systems that deliver real, measurable value. You’re no longer just building an automation; you’re engineering a reliable, optimized, and production-ready AI solution.
The post How to stop your AI agents from hallucinating: A guide to n8n’s Eval Node appeared first on LogRocket Blog.
This post first appeared on Read More